Joshua Krcmar, Nicolas Teusch, Jonas Sannewald & Andreas Pelligra
Instalife in Mannheim
Soziale Netzwerke haben in den letzten Jahren eine immer größer werdende Bedeutung in der Gesellschaft eingenommen. Neben Facebook, Twitter und Snapchat wird insbesondere Instagram für den internetbasierten Informationsaustausch verwendet. Besonders interessant wird dies bei der Betrachtung von urbanen Räumen, über die besonders viele Informationen ausgetauscht werden. Geschuldet ist dies in der Regel der hohen Bevölkerungsdichte und der hohen Anzahl an Sehenswürdigkeiten, Veranstaltungsorten und anderen Freizeitangeboten. Das Projekt Instalife zeigt, dass sich nur durch die Auswertung von Instagram-Beiträgen und den damit gekoppelten Positionsangaben reale Events im urbanen Raum erkennen lassen. Die so entstandene Schnittmenge zwischen virtuellen Beiträgen und realen Events an bestimmten Lokalitäten wird durch die Visualisierung hervorgehoben.
Gliederung
Einführung
Die Ideenfindung für ein angemessenes Projekt zum Thema „Urbanität und Smart Cities“ fiel uns zu Beginn nicht leicht. Insbesondere die Vorgabe der ausschließlichen Betrachtung von urbanen Daten, beispielsweise von Sensoren oder Systemen, die Daten über die Stadt sammeln, hat uns die Themenfindung erschwert. Lediglich fertige Datensätze aus öffentlichen Informationsportalen (beispielsweise Opendata Mannheim) zu verwenden und angemessen zu visualisieren, fanden wir als Gruppenprojekt einstimmig unattraktiv. Für uns war aus diesem Grund bereits zu einem sehr frühen Zeitpunkt klar, dass die Datenbeschaffung einen besonderen Teil des Projekts einnehmen wird.
Da zu diesem Zeitpunkt innerhalb der Gruppe allerdings noch nicht klar war, welche Daten beschafft werden sollen und welche These mit dieser Datenbasis diskutiert werden soll, haben wir das Internet nach Visualisierungsprojekten zum Thema Urbanität durchsucht. Im Laufe dieser Recherche sind wir auf ein Projekt von Eric Fischer gestoßen, der in Zusammenarbeit mit MapBox und Gnip eine Visualisierung mithilfe von Twitter-Daten geschaffen hat.

Die blauen Punkte auf der Karte kennzeichnen Twitter-Beiträge (nachfolgend „Tweets“) von lokal ansässigen Personen, die mindestens einen Monat Tweets in dieser Region abgesendet haben.
Die roten Punkte hingegen kennzeichnen Touristen, also Personen die weniger als einen Monat Tweets in dieser Region abgesendet haben. Die Visualisierung kann über diesen Link interaktiv bedient werden: Link.
Angelehnt an das Projekt von Eric Fischer haben wir uns aufgrund der aktuellen Popularität und der zunehmenden Ablösung von Facebook für ein Projekt mit Instagram-Daten entschieden. Um dem Thema Urbanität gerecht zu werden, verwenden wir im Rahmen dieses Projekts ausschließlich Instagram-Beiträge, die einen Bezug zu einer Großstadt haben - in diesem Fall Mannheim.
Hypothese
Aufgrund der extrem großen Datenbasis war auch die Hypothesenfindung in unserem Fall nicht ganz trivial. Zu Beginn hatten wir viele Ideen, welche Aussagen oder Schlüsse aus den Instagram-Beiträgen gezogen werden können. Eine vielversprechende Annahme zu Beginn war, dass ein urbaner Raum, in unserem Fall die Stadt Mannheim, lediglich mit Instagram-Beiträgen rekonstruierbar ist. Im Fokus stand bei dieser anfänglichen Idee das soziale Leben, wodurch beispielsweise beliebte Orte oder Hotspots auf einer Karte sichtbar gemacht oder die politische Stimmung, zum Beispiel zur Bundestagswahl, erkennbar werden sollte. Sobald wir uns intensiver mit den vorhandenen Instagram-Daten beschäftigt haben, wurden diese anfänglichen Ideen allerdings stark beschränkt. Durch diverse Limitierungen seitens Instagram und insbesondere der erheblichen Datenmenge waren einige Ideen nicht mit einem angemessenen Aufwand umsetzbar.
Im Vergleich zum gesamten Projekt nahm die konkrete Hypothesenfindung und der Prozess der Projektplanung, wie im vorherigen Kapitel beschrieben, einen großen Teil ein. Rückblickend fanden wir in diesem Zusammenhang die verpflichtenden Konsultationen mit Professor Doktor Nagel sehr sinnvoll. Im Rahmen dieser Besprechungen konnten wir unsere Planung kontinuierlich besprechen und haben konkrete Rückmeldungen zu unseren Ideen bekommen. Dies hat uns bei der Hypothesenfindung extrem weitergeholfen und unsere Problematik der zu vielen Ideen und Visualisierungsmöglichkeiten konnte gemeinsam gelöst werden.
Letztendlich haben wir uns auf die Hypothese festgelegt, dass sich Events an bestimmten Lokalitäten nur durch Instagram-Beiträge erkennen lassen. Dies war ein Kompromiss zwischen Umsetzbarkeit seitens Instagram und der entstehenden Datenmenge, die für eine performante Umsetzung nicht zu groß werden sollte. Ein Beispiel hierfür wäre, dass der Weihnachtsmarkt am Mannheimer Wasserturm mithilfe von Instagram erkannt werden kann. Welche weiteren Aussagen sich durch die Visualisierung erkennen lassen, blieb bis zu diesem Stand natürlich offen.
Arbeit mit den Daten
Die Arbeit mit den Daten nahm in unserem Projekt eine besonders große Rolle ein. Der im Vergleich zu anderen Projekten dieses Semesters erhebliche Zeitaufwand für die Datenbeschaffung, die den Grundstein für unser Projekt gelegt hat, war der generellen Unzugänglichkeit der Daten geschuldet. Instagram bietet nämlich keine offizielle Schnittstelle an, über die wir die benötigten Daten von deren Servern hätten beziehen können. Nach dem Beschaffen der Daten war die extrem große Datenbasis ein weiteres Problem, das viel Zeit gekostet hat. Hier ist insbesondere die ungeeignete Datenrepräsentation zu nennen, die die Datenbasis unnötig vergrößert hat. So waren nicht nur die relevanten Werte, beispielsweise Uhrzeit und Textbeschreibung des Instagram-Beitrags, in der Datenbasis enthalten, sondern viele weitere Daten, die für das Projekt nicht relevant waren. Damit ist im Vergleich zu fertigen Datensätzen, wie sie beispielsweise von Open-Data Portalen angeboten werden, wesentlich schwieriger umzugehen. Aufgrund dieser Komplexität beim Umgang mit den für das Projekt notwendigen Daten, mussten wir vergleichsweise viel Zeit für diese Arbeit investieren.
Beschaffung und Analyse
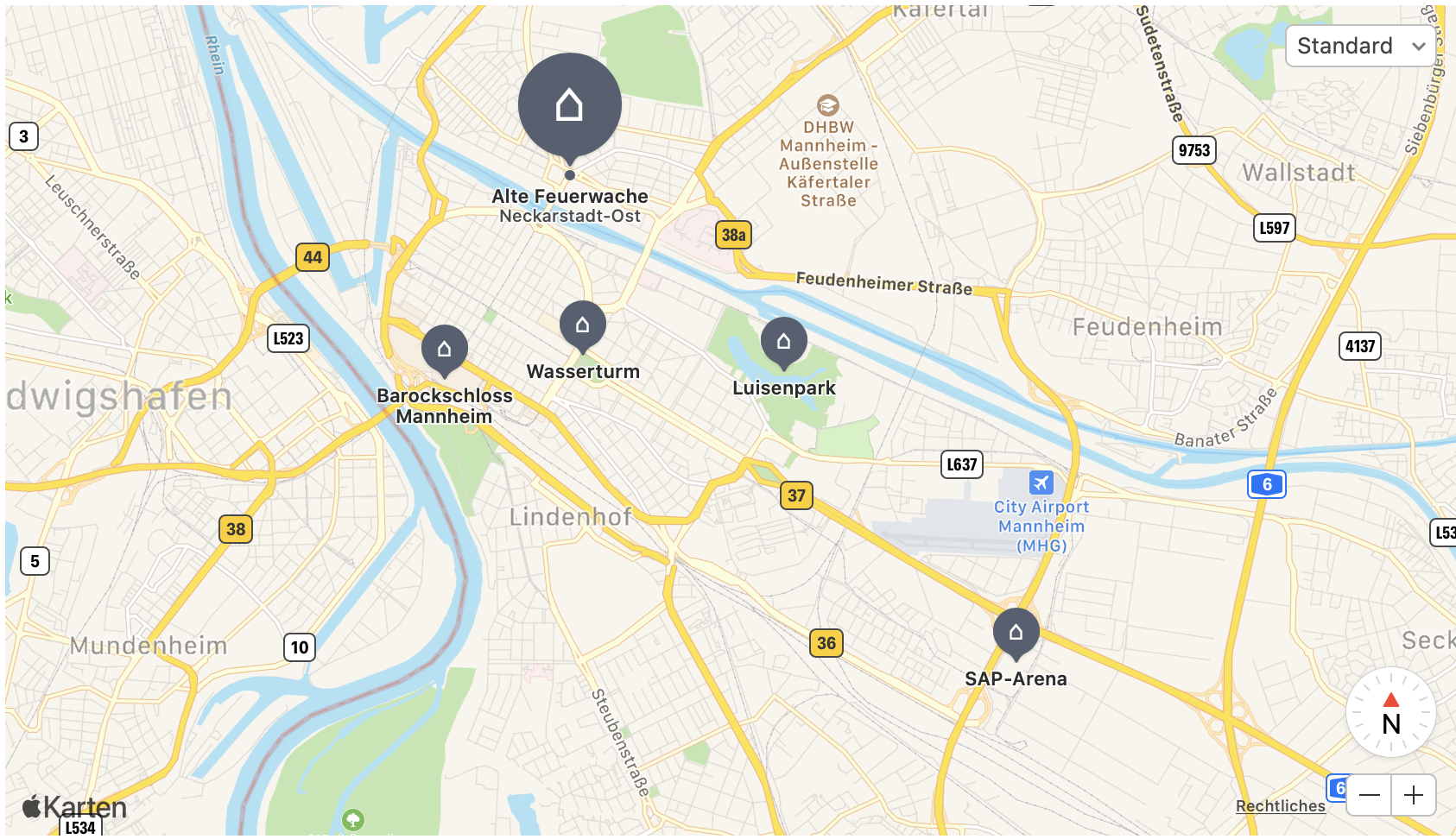
Auf Basis der Hypothese, die es im Rahmen unseres Projekts zu bestätigen galt, haben wir uns dazu entschlossen, lediglich Instagram-Beiträge mit einer bestimmten Positionsangabe herunterzuladen. Als Positionsangabe haben wir uns für die Lokalitäten Alte Feuerwache, Barockschloss, Wasserturm, SAP-Arena und Luisenpark entschieden. Hintergrund dieser Entscheidung war, dass sowohl Veranstaltungsorte, bei denen Events erwartet werden, als auch beliebte Örtlichkeiten, bei denen Events nicht unbedingt zu erwarten sind, in der Auswahl enthalten sind. Ein weiterer wichtiger Grund war, dass diese Lokalitäten bekannt für Mannheim sind und so generell viele Instagram-Beiträge dazu vorhanden sind. Die Auswahl war auf Basis dieser Begründung nicht ganz trivial, da Orte, bei denen wir viele Instagram-Beiträge erwartet hätten, oftmals nur sehr wenig erwähnt wurden. Als Beispiel ist hier insbesondere der Mannheimer Fernmeldeturm zu nennen.
Für uns waren neben den gerade erwähnten Lokalitäten insbesondere die Zeitstempel, also das Datum inklusive der Uhrzeit, und die mit dem Instagram-Beitrag verbundenen Hashtags interessant. Neben diesen Daten, bietet Instagram speziell für Nutzer mit Einschränkungen (z.B. blinde Personen) so genannte „accessibility descriptions“ an. Das sind textuelle Beschreibungen der Bilder, die eingeschränkten Nutzern als weitere Interpretationsmöglichkeit zur Verfügung gestellt werden. Die Beschreibungen werden dabei seitens Instagram mithilfe einer künstlichen Intelligenz erzeugt. Ein Beispiel hierfür wäre: „Image may contain: one or more people, people standing and outdoor“. Auf diese KI-Beschreibungen sind wir durch Zufall gestoßen, als wir die Metadaten der Instagram-Bilder durchgesehen haben. Nach dieser Erkenntnis war es uns ein großes Anliegen, diese Daten in unser Projekt mit einzubeziehen. Wir erhofften uns dadurch, bessere Aussagen über die Art des Events und die Form der Lokalität treffen zu können. Beschreibungen wie „people playing sports“ sind ein klarer Hinweis darauf, dass an dieser Lokalität Sportevents stattfinden. Ein logischer Schluss daraus wäre, dass die Lokalität ein Sportstadion ist.
Aufgrund der fehlenden öffentlichen Schnittstelle (API) von Instagram, die uns die für das Projekt notwendigen Daten liefert, mussten wir zur Datenbeschaffung auf ein externes Tool zurückgreifen. Der Quellcode dieses Projekts mit dem Namen Instaloader ist auf GitHub zugänglich: Link. Mithilfe dieses Tools war es uns möglich, die oben erwähnten Daten herunterzuladen. Instaloader bietet neben der Bedienung über die Kommandozeile auch noch ein Python-Modul an, mit dem ein eigenes Python Programm um Funktionalitäten erweitert werden kann.
Über die Kommandozeile haben wir alle Instagram-Beiträge einer bestimmten Lokalität vom 01.01.2019 bis 01.01.2020 heruntergeladen:
instaloader --post-filter="date_utc <= datetime(2020, 1, 1) and date_utc >= datetime(2019, 1, 1)"
--no-pictures --no-videos --no-video-thumbnails --no-compress-json
%LOCATION-ID --login USER --password PASSWORD→ Code-Snippet zum Herunterladen von Instagram-Beiträgen über die Kommandozeilenanwendung von Instaloader
Instaloader sendet zur Beschaffung dieser Daten eine erhebliche Anzahl an HTTP-Requests an Instagram, weswegen es mehrfach zu einer serverseitigen temporären Sperre unserer für das Projekt erstellten Benutzeraccounts kam. Diese Sperre äußerte sich dadurch, dass Instaloader die Fehlermeldung „too many requests“ zurückgab. Das war problematisch, da so eine inkonsistente Datenbasis entstehen konnte. Um die Konsistenz zu gewährleisten, haben wir in solchen Fällen einige Stunden gewartet und den gesamten Zeitraum erneut heruntergeladen.
Wenn das Instaloader-Tool erfolgreich abgeschlossen wurde, ist ein neuer Ordner mit allen Instagram-Beiträgen mit der Angabe der entsprechenden Lokalität entstanden:
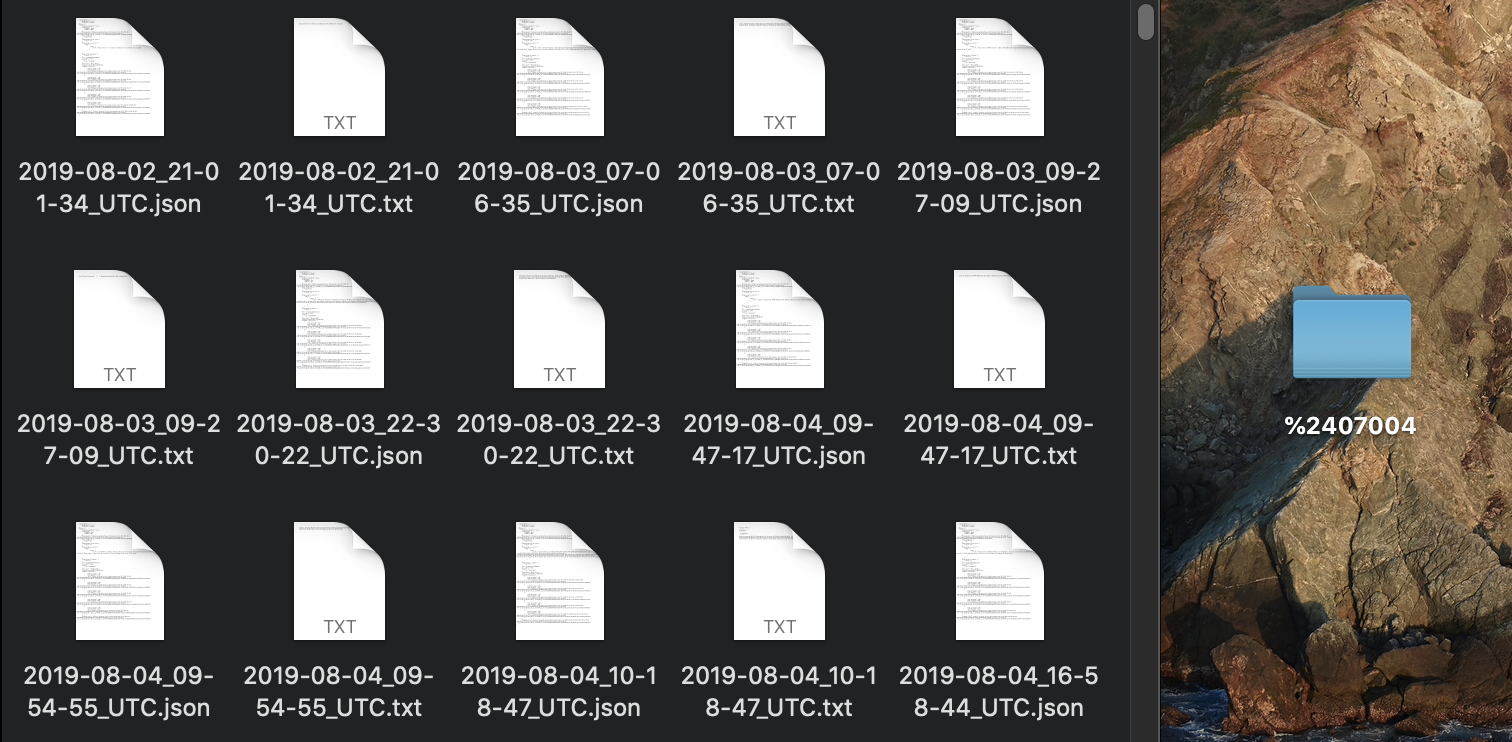
Eine weitere Problematik war, dass Instagram nicht verhindert, dass es mehrfach die gleiche Lokalität gibt. So gibt es beispielsweise das Barockschloss mit der Universität insgesamt 10 Mal auf Instagram. Der hier beschriebene Vorgang ist also ausschließlich für diese Lokalität 10 Mal zu wiederholen.
In dem oben genannten Ordner sind für jeden Instagram-Beitrag zwei neue Dateien entstanden: eine JSON-Datei, die alle Metadaten zu dem Beitrag enthält und eine TXT-Datei, die den eigentlichen Text inklusive der Hashtags des Beitrags enthält.
Leider enthalten die mit Instaloader heruntergeladenen Dateien nicht die Beschreibung der künstlichen Intelligenz. Bis zuletzt konnten wir keine entsprechende Konfiguration für das Tool finden, sodass die KI-Beschreibungen mit heruntergeladen werden. Aus diesem Grund mussten wir ein Python-Skript schreiben, das die heruntergeladenen Dateien nochmal lokal durchläuft, für jeden Beitrag den JSON-Eintrag „shortcode“ ausliest und mithilfe dieses Codes eine erneute Anfrage für das spezielle Bild stellt. Für die Anfrage wird das Instaloader Python-Modul genutzt und die Rückgabe des Moduls wird anschließend in die vorhandene JSON-Datei geschrieben. Die Datei mit den Metadaten wird also um einen weiteren JSON-Eintrag erweitert:
[…],
"gdv_tool": "Image may contain: one or more people and indoor“ }→ Beispiel für die Erweiterung der JSON-Datei mit der neuen KI-Beschreibung
Das Python-Skript kann hier heruntergeladen werden: Link.
In diesem Status sind zwar alle notwendigen Daten vorhanden, allerdings in einem Repräsentationsformat, das für unsere Zwecke ungeeignet ist. Zudem sind sehr viele zusätzliche Metadaten enthalten, die für die Visualisierung irrelevant sind und so den Datensatz nur unnötig vergrößern. Um dieses Problem zu lösen, haben wir ein weiteres JavaScript geschrieben, das die relevanten Informationen aus den lokalen Dateien ausliest (z.B. Text, Hashtags, KI-Beschreibung usw.) und diese dann normalisiert in einer Datenbank speichert. So minimieren wir die Größe der Datenbasis drastisch und können eine höhere Performance erreichen. Ein weiteres JavaScript durchläuft anschließend die Datenbank und ersetzt die leserlichen Zeitstempel in UNIX-Zeitstempel. Dabei ist zu beachten, dass alle Instagram-Beiträge an einem Tag den gleichen UNIX-Zeitstempel bekommen, um die Ladezeiten erheblich zu verringern. Die Visualisierung kann somit nicht unterscheiden, um wie viel Uhr der jeweilige Beitrag erstellt wurde, lediglich der Tag ist für uns relevant.
Das JavaScript zum Füllen der Datenbank kann hier heruntergeladen werden: Link.
Das JavaScript zum Anpassen der Zeitstempel kann hier heruntergeladen werden: Link.
Die Datenbasis, die wir letztendlich für das Projekt verwendet haben, stand nach dem obigen Vorgehen normalisiert in einer Datenbank. Der Prozess zum Aufbau der Datenbasis bestand somit aus sehr vielen Schritten, die für jede Lokalität, die es seitens Instagram sogar mehrfach gab, wiederholt werden musste. Dieser Prozess nahm leider einen Großteil der Zeit für das Projekt ein.
Experimentelle Visualisierungen
Sowohl die Ideenfindung für das Projekt als auch die Auswahl der Hypothese zusammen mit der Datenbeschaffung und Analyse nahm in unserem Projekt sehr viel Zeit in Anspruch. Da zudem die Zeit für das Gesamtprojekt vergleichsweise kurz war, konnten wir leider nicht so viele Visualisierungsexperimente durchführen, wie wir das gerne gemacht hätten. Hätten wir weitere Zeit für tiefergehende Visualisierungsexperimente investiert, wäre unser Prototyp zur iExpo vermutlich nicht fertig geworden. Aus diesem Grund stellen wir hier lediglich die Experimente vor, die ein zufriedenstellendes Ergebnis geliefert haben. Eine fundierte Erklärung, warum wir uns für welche Visualisierung entschieden haben, erfolgt erst im Kapitel „Visualisierungen“ und ist ausdrücklich nicht Teil dieser Vorstellung der Experimente.
Die Visualisierung der KI-Beschreibungen stellte uns vor eine große Herausforderung, weil wir mögliche Texte nicht vorhersehen konnten. Da es die unterschiedlichsten Beschreibungen geben konnte, haben wir uns zu Beginn darauf geeinigt, als Visualisierung lediglich Text anzuzeigen. Da dafür die einfachste Möglichkeit eine WordCloud ist, haben wir damit Experimente durchgeführt.


Nachdem wir zur Visualisierung der Hashtags gekommen sind, standen wir allerdings vor dem gleichen Problem wie zuvor auch schon bei den KI-Beschreibungen. Wir hatten viel Text, der bei der großen Datenbasis nicht vorhersehbar war und mussten diesen irgendwie visualisieren. Da uns zu diesem Zeitpunkt keine sinnvolle Alternative eingefallen ist, haben wir versucht die Hashtags ebenfalls in einer WordCloud darzustellen.

Im Rahmen unserer Visualisierungsexperimente ist uns aufgefallen, dass sich bei den unterschiedlichen WordClouds der KI-Beschreibungen die gleichen Textbausteine immer wiederholen. Dies war bei den Hashtags nicht erkennbar, da diese in der gesamten Datenbasis nur eine geringe Schnittmenge haben. Aufgrund dieser Erkenntnis haben wir uns dazu entschlossen, die KI-Beschreibungen anders zu visualisieren. Spontan sind uns hierfür Emojis eingefallen, da diese sehr gut auf die atomaren Beschreibungen der künstlichen Intelligenz passen. Da es hierfür keine fertige Software gab, haben wir selbst einen experimentellen Prototyp für die Darstellung erstellt.
→ Viertes Visualisierungsexperiment mit einem experimentellen Prototypen zur Darstellung der KI-Beschreibungen
Unser Dashboard für den Prototypen haben wir uns zu diesem Zeitpunkt so vorgestellt.
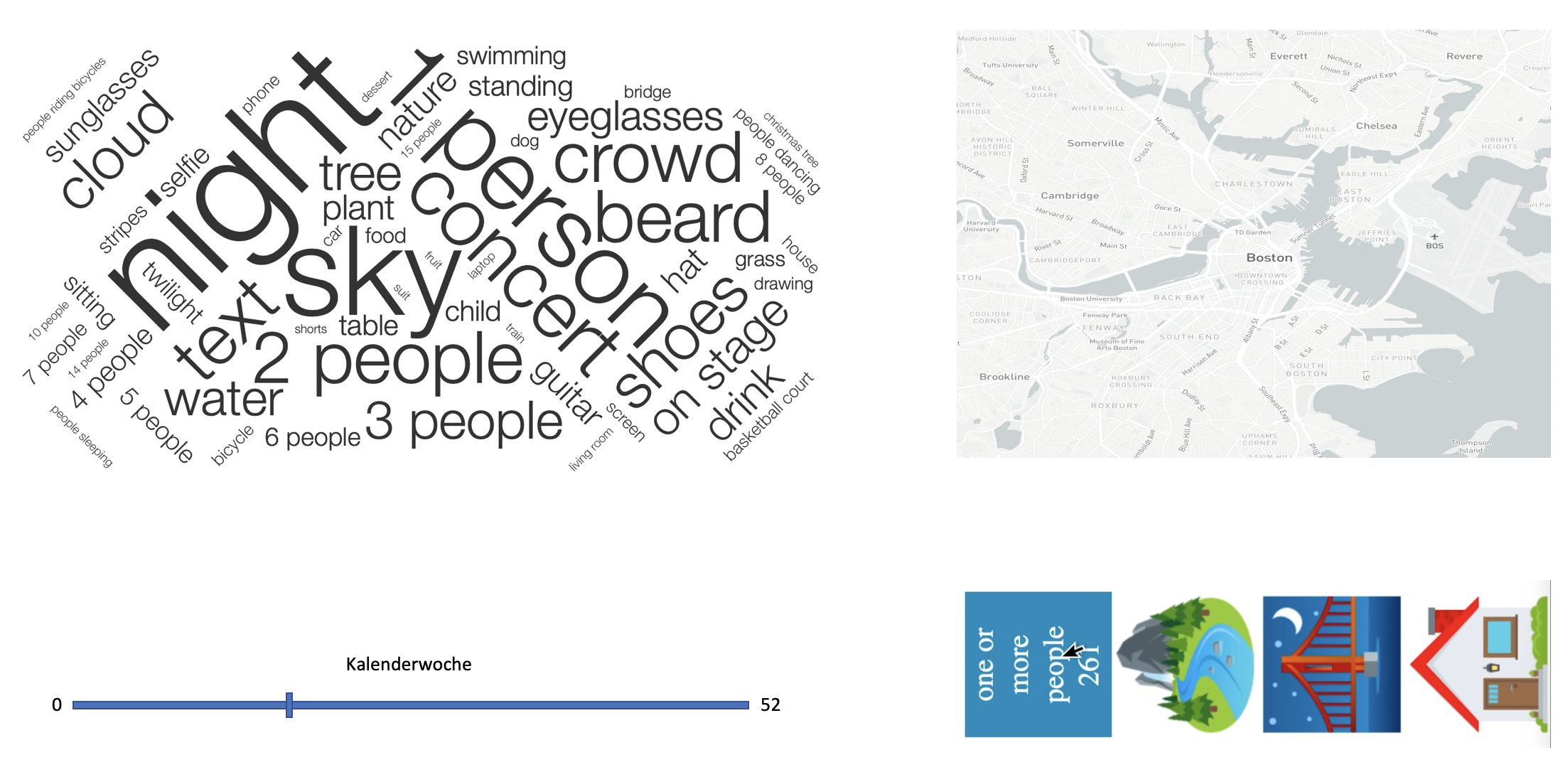
Umsetzung des Prototyps
Innerhalb unserer Gruppe war schnell klar, dass unser Prototyp auf Webtechnologien basieren soll, da wir alle gut mit den entsprechenden Sprachen und Konzepten umgehen können. Ein weiterer Punkt für diese Entscheidung war, dass wir es uns offen halten wollten, den Prototypen im Internet zu veröffentlichen. Neben einer klaren Raumtrennung unserer Web-Applikation (nachfolgend nur noch „WebApp“), wollten wir eine Darstellungsanpassung für mobile Geräte ausdrücklich nicht unterstützen. Unsere WebApp ist für große Bildschirme ausgelegt und kann auch nur mit solchen intuitiv und ansprechend benutzt werden.
Nachfolgend ist ein erster Eindruck des Prototyps zu finden.

Visualisierungen
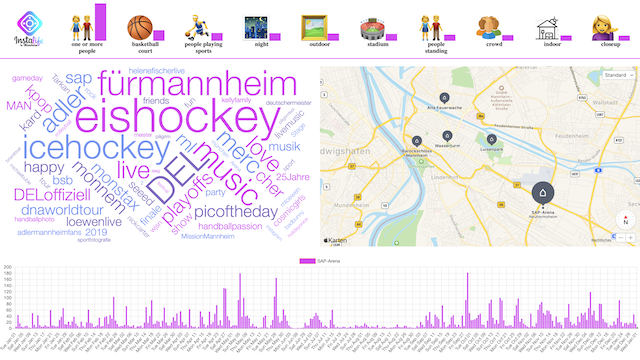
Für die Erklärung der Visualisierungen haben wir uns für die Auswahl der Lokalität Alte Feuerwache mit dem Zeitraum des gesamten Jahres entschieden. Die nachfolgenden Visualisierungen zeigen also die entsprechenden Daten an.
Die WordCloud haben wir für die Hashtags ausgewählt, um zum einen möglichst viele Hashtags anzeigen zu können. Denn auch Hashtags, die vergleichsweise wenig erwähnt wurden, können Hinweise zu wichtigen Events geben. Als Beispiel kann hier in der WordCloud „fake“, „gdv“, und „visualisierung“ genannt werden. Diese werden deswegen angezeigt, weil bei unserer Zwischenpräsentation Kommilitonen Instagram-Beiträge verfasst haben, um unsere Visualisierung zu testen. Zum anderen werden in der WordCloud die Hashtags, die eine hohe Aussagekraft haben, da sie häufig erwähnt wurden, groß dargestellt. So kann auch zwischen den Hashtags, also zwischen Events bzw. deren Bezeichnungen, eine Relevanz festgestellt werden. Da uns bewusst ist, dass ein Benutzer nicht mit jedem Begriff in der WordCloud (beispielsweise „lgbt“) etwas anfangen kann, wird durch Anklicken des entsprechenden Hashtags eine Google-Suche in einem neuen Tab gestartet. Der Benutzer erkennt diese Funktionalität daran, dass die Hashtags ihre Farbe leicht ändern, sobald mit dem Mauszeiger darüber gefahren wird.

Bei der Map haben wir uns aus optischen Gründen für Apple Maps entschieden. Im Vergleich zu Leaflet-Karten sehen die Apple-Karten ansprechender aus und sind so für unsere Visualisierung besser geeignet. Wir haben bewusst einen relativ weiten Zoom aus Mannheim heraus gewählt, um alle verfügbaren Lokalitäten übersichtlich anzeigen zu können. Damit der Benutzer zu jeder Zeit erkennt, welche Lokalität gerade ausgewählt ist, wird der Marker der ausgewählten Lokalität vergrößert dargestellt. Zudem wird unter dem Namen der Lokalität der entsprechende Ortsteil eingeblendet, um weitere Informationen zum Standort der Lokalität zu erhalten. Ein Wechsel der Lokalität ist intuitiv möglich, indem auf einen anderen Marker gedrückt wird.
Das Barchart haben wir ausgewählt, um alle Instagram-Beiträge pro Tag anzuzeigen. So können effektiv bestimmte „Ausreißer“ erkannt werden. Werden an einem Tag sehr viele Beiträge geschrieben, ist die Wahrscheinlichkeit sehr hoch, dass an diesem Tag auch ein besonderes Event stattfand. Das Säulendiagramm zeigt daher insgesamt 365 Säulen, für jeden Tag des Jahres eine. Wir haben versucht, als Alternative einen Stacked-Area-Graphen zu implementieren, dies war aufgrund der Datenmasse und der Auswahl des Zeitraum aber nicht effektiv umsetzbar. Damit der Benutzer auch beim Barchart jederzeit sieht, welche Lokalität gerade ausgewählt ist, wird diese über dem Säulendiagramm nochmals angezeigt. Um die X-Achse des Barcharts nicht zu überladen, sodass der Benutzer keine Übersicht mehr hat, haben wir auf eine kontinuierliche Bezeichnung jeder Säule verzichtet und nur jede vierte Säule mit einem Datum bezeichnet. Sobald der Benutzer aber mit dem Mauszeiger über eine bestimmte Säule fährt, werden alle Informationen (Datum, Lokalität und Anzahl der Beiträge) nochmals angezeigt.
Wir haben uns dazu entschlossen, das Barchart mit der Zeitauswahl zu kombinieren, da so kein separater Range-Slider notwendig gewesen ist und wir davon überzeugt sind, dass die Tagauswahl im Barchart grundsätzlich intuitiver ist. Damit der Benutzer sofort erkennt, welcher Bereich gerade ausgewählt ist, wird der markierte Zeitraum mit lila Säulen angezeigt. Tage, die bei der Visualisierung nicht betrachtet werden, sind dann grau hinterlegt. Die Auswahl des Zeitraums erfolgt über einen Links- und einen Rechtsklick.


Für die Emojibar haben wir uns zu einer Anzeige von Emoji-Icons entschlossen. Da die künstliche Intelligenz oftmals die gleichen Wortschnipsel konkateniert, fanden wir diese Form der Visualisierung passend und ansprechend. Insbesondere, da Emojis in den letzten Jahren im Rahmen von sozialen Medien eine immer größere Rolle einnehmen, fanden wir diese Darstellungsform für unser Projektthema passend. Da Emojis aber teilweise nicht eindeutig sind, haben wir uns dazu entschieden, die Originalbeschreibung in Textform unter die Emojis zu setzen. So erkennt der Benutzer zwar mit einem Blick, welche Dinge die künstliche Intelligenz grundsätzlich auf den Bildern in den Instagram-Beiträgen erkannt hat, kann bei Doppeldeutigkeiten aber nochmals die genaue Beschreibung lesen. An dieser Stelle sei auch der Vorteil der nonverbalen Informationsvermittlung genannt: ein Benutzer muss bei der Emojibar nicht zwingend Englisch beherrschen, um zu verstehen, was die Bilder in den Beiträgen enthalten. Im Zusammenhang mit der Emojibar ist die Anzahl der einzelnen Nennungen durch die künstliche Intelligenz ebenso wichtig. Aus diesem Grund haben wir uns als Visualisierung für einfache Balken neben den Emojis entschieden, die relativ zur absoluten Anzahl der Nennung eine entsprechende Höhe haben. Damit verhindern wir falsche Schlüsse, falls ein Emoji an der zweiten Stelle in der Emojibar auftaucht, aber nur halb so oft genannt wurde wie das erste Element. Mithilfe dieser Visualisierung stellt der Benutzer also mit nur einem Blick fest, was die künstliche Intelligenz auf den Bildern in den Beiträgen erkannt hat und wie oft diese Beschreibung vorkam. Sobald mit dem Mauszeiger über das Emoji gefahren wird, wird die absolute Zahl der Nennungen eingeblendet. Dies wollten wir bewusst aus der Initialsicht herauslassen, um die Visualisierung nicht zu überladen. Letztendlich kann der Benutzer mithilfe der Emojibar Schlüsse über die Art des Events und die Form der Lokalität ziehen.

Unser Dashboard hat bewusst einen sehr klar strukturierten Aufbau. Die Emojibar und das Barchart begrenzen das Dashboard nach oben und nach unten und nehmen die gesamte Breite ein. In der Mitte teilen sich die WordCloud und die Map die gesamte Bildschirmbreite. Durch diesen klaren Aufbau erhoffen wir uns, dass das Dashboard nicht überladen wirkt und der Einstieg für den Benutzer nicht zu kompliziert ist. Im Rahmen unserer Präsentation auf der iExpo haben wir damit sehr gute Erfahrungen gemacht und diesbezüglich ausschließlich positives Feedback bekommen.
Implementierung
Da unsere WebApp auf vielen unterschiedlichen Technologien basiert, macht es Sinn, die Technologien zu unterteilen. Zum einen in Systemtechnologien und zum anderen in Visualisierungstechnologien. Für das System haben wird uns aufgrund der Performance für Node.js als Backend entschieden. Das Backend beliefert in unserem Fall ausschließlich das Frontend mit Initialdaten und aktualisierten Anzeigedaten. Als Datenbank haben wir uns für den MySQL-Fork MariaDB entschieden. Darin ist unsere Datenbasis gespeichert und wird vom Backend abgerufen. Da wir die WebApp auf unterschiedlichen Rechnern entwickelt haben, haben wir uns für Docker entschieden, um Container schnell untereinander auszutauschen.
Für jede unserer Visualisierungen haben wir unterschiedliche Technologien verwendet. Aus diesem Grund erfolgt die Erklärung der Implementierung nun nacheinander anhand der Visualisierungen.
Die WordCloud wurde über Vega realisiert. Das Generieren der WordCloud mit den Hashtags, die in der Datenbank stehen, gestaltete sich als relativ trivial. Die erweiterte Funktionalität, dass sich beim Anklicken eines Hashtags eine Google-Suche in einem neuen Fenster öffnet, war allerdings nicht so einfach. Das Registrieren von Eventhandlern in Vega empfanden wir daher als nicht ganz so einfach. Ein weiteres Problem tauchte bei der Performance auf, da die WordCloud sehr lange brauchte, um sich im Frontend zu generieren. Der Grund dafür war, dass der WordCloud eine einfache Zeichenkette mit den Hashtags übergeben wurde, die dann im Frontend nach mehrfach vorkommenden Worten durchsucht wurde. Da dies auch nicht effizient vorberechnet werden konnte, haben wir uns dazu entschieden, die darzustellende Größe eines Hashtags bereits über die MariaDB zu berechnen. Statt einem einfachen String wurde nun ein Array mit JSON-Objekten an die WordCloud übergeben. So konnte eine merkliche Verbesserung der Performance erreicht werden.
“Mannheim Mannheim Mannheim Wasserturm Wassertum”→ Alte Methode, der WordCloud die Werte zu übergeben
[{“count”: 3, “text”: “Mannheim”}, {“count”: 2, “text”: “Wasserturm”}]→ Neue Methode, der WordCloud die Werte zu übergeben
Für die Map haben wir uns zu Beginn für Leaflet entschieden, da die Umsetzung damit sehr trivial war. Insbesondere die für uns wichtige Operation, also das Registrieren von Eventhandlern auf den Positionsmarkern (z.B. Wasserturm, Alte Feuerwache usw.), war mit Leaflet sehr schnell umzusetzen. Da uns das Design von Leaflet aber im Laufe der Entwicklung kontinuierlich immer weniger zusagte, entschieden wir uns dazu, auf Apples MapKit JS umzusteigen. Die Migration der vorhandenen Code-Teile auf das neue Kartensystem war zum Glück nicht kompliziert. Dadurch, dass ein Gruppenmitglied bereits einen Apple Developer Account hatte, war die Beschränkung der API von MapKit JS auch kein Problem.
Das Barchart wollten wir zu Beginn ebenfalls mit Vega realisieren, haben uns im Laufe der Entwicklungsphase aber recht schnell dagegen entschieden. Hintergrund dieser Entscheidung ist, dass sich das Verknüpfen der anderen Bestandteile unserer WebApp wie die Map und die WordCloud mit Hilfe von Vega als äußert kompliziert herausstellte. Da wir auch aufgrund der nahenden Präsentation des Prototypens auf der iExpo nicht mehr viel Zeit in mögliche Sackgassen investieren wollten, haben wir uns dann für eine weitere JavaScript Bibliothek entschieden. Mithilfe von Chart.js konnten wir ziemlich schnell und einfach die notwendigen Eventhandler umsetzen. Auch die Zeitauswahl mit einem Links- und einem Rechtsklick konnte mit Chart.js besonders schnell umgesetzt werden.
Die Emojibar ist die einzige Visualisierung, die komplett ohne externe Software umgesetzt wurde. Die Sprachen HTML, CSS und JavaScript reichten für die Umsetzung mit ihren Standardfunktionalitäten vollumfänglich aus.
In unseren Augen ist Vega zwar ein sehr gutes Tool, das dem Programmierer sehr viele Möglichkeiten bietet, allerdings ist es auch sehr komplex und damit schwer zu erlernen, was bei uns zu vielen Hindernissen führte. Falls es zum „daily businesses“ eines Programmierers gehört, Visualisierungen zu erstellen, ist Vega sicher keine schlechte Wahl. Für ein kleineres Projekt wie dieses, war es für uns jedoch besser auf andere Technologien zurückzugreifen, um mit einfacheren Mitteln ans Ziel zu kommen.
Erkenntnisse und weiterführende Ideen
Unser Ziel war es zu jeder Zeit, eine Visualisierung zu schaffen, die unsere Hypothese bestmöglich stützt. In unserem Fall stand also ganz klar die Erkennung von Events an den ausgewählten Lokalitäten im Vordergrund. Was wir in der Planungsphase zwar gehofft aber nicht wissen konnten, war, dass sich durch unsere Visualisierung auch noch weitere Erkenntnisse folgern lassen. Nachfolgend werden nun die interessantesten Erkenntnisse vorgestellt. Dies sind ausdrücklich nicht alle Schlüsse und Informationen, die sich mithilfe der Visualisierung erkennen lassen. Eine erschöpfende Auflistung ist aufgrund der Rahmenbegrenzung dieses Dokuments leider nicht möglich.
Events lassen sich tatsächlich durch unsere Visualisierung erkennen. Wir können nicht nur populäre Events, die in Mannheim bekannt sind, erkennen, sondern auch Events, die weniger bekannt sind. Unsere Hypothese ist damit eindeutig bestätigt: Events an bestimmten Lokalitäten lassen sich nur durch Instagram-Beiträge erkennen!
Beispielsweise wird am Barockschloss Mannheim am 10. August der CSD (Christopher Street Day) gefeiert. Dieses Großevent sticht bei der Ansicht der am Tag geschriebenen Instagram- Beiträgen klar heraus. Wählt man den entsprechenden Bereich im Barchart aus, erkennt man in der WordCloud die Hashtags „pride“, „csd“, „gay“ und „csdrheinneckar“. Diese lassen uns ganz klar den Christopher Street Day erkennen. Wir hätten dieses Event somit auch ohne Kenntnisse über Mannheim und den CSD erkannt.


Aber auch kleine Events werden zuverlässig erkannt. Im Besonderen sollte hier die Alte Feuerwache erwähnt werden, bei der regelmäßig kleinere Events stattfinden. Hervorheben möchten wir den 07. bis 09. November. An diesen Tagen waren laut Archiv der Alten Feuerwache drei Konzerte hintereinander: Teesy (07.11), Spotlight Polen (08.11) und La Nuit Boheme (09.11). Dies waren vergleichsweise kleine Konzerte, die aber dennoch zuverlässig durch unsere Visualisierung erkannt werden können.


Eine weitere Erkenntnis ist, dass die Angaben der künstlichen Intelligenz sehr zuverlässig sind und tatsächlich bei der Identifizierung des Events weiterhelfen. So werden beispielsweise klare Hinweise zum Event als solches gegeben aber zusätzlich auch noch zur Lokalität. Würde unser Projekt in einer fremden Stadt eingesetzt werden, könnte sich so ermitteln lassen, um welche Art von Lokalität es sich hierbei handelt. Die Effektivität dieser KI-Angaben möchten wir mit den nachfolgenden Beispielen beweisen.
Am 27. August war der Bassist der Guns N‘ Roses Band in der Alten Feuerwache Mannheim. Unsere Emojibar, die die Angaben der künstlichen Intelligenz visualisiert, gab dabei an, dass auf den Bildern „people on stage“, „people playing musical instruments“, „guitar“ und „concert“ zu sehen ist.

Wählt man hingegen bei der SAP-Arena das gesamte Jahr aus, werden auf der Emojibar einige Hinweise zur Lokalität angezeigt. Besonders interessant ist in diesem Zusammenhang die Nennung von „basketball court“, „people playing sports“, „stadium“ und „crowd“.

Eine weitere Erkenntnis ist, dass wir mithilfe unserer Visualisierung nicht nur Events als solches erkennen können, sondern auch bemerken, wenn Events „fehlen“. Aufgefallen ist uns das, als wir uns das gesamte Jahr der SAP-Arena angesehen haben. Über die WordCloud haben wir erkannt, dass sich in der SAP-Arena zwei Events kontinuierlich wiederholen: Eishockey und Handball. Allerdings gibt es im Juli und August starke Einbußen der täglichen Instagram-Beiträge. Nach einer Recherche bezüglich den Spielplänen der DEL und HBL konnten wir eine Spielpause in dem genannten Zeitraum feststellen. Mithilfe der Visualisierung können wir also nicht nur Events sondern auch Spielpausen erkennen.


Hier nur am Rande möchten wir erwähnen, dass sogar Events erkannt werden, die gar nicht an unseren ausgewählten Lokalitäten stattfinden. Zu nennen ist hier insbesondere die „Animagic“, die im Rosengarten Mannheim stattfindet. An unserer Lokalität Wasserturm gibt es an den Veranstaltungstagen der Animagic erhebliche Ausschläge bezüglich den täglichen Instagram-Beiträgen, obwohl das eigentliche Event ca. 300 Meter weiter weg stattfindet.
Natürlich ist der jetzige Stand lediglich ein Prototyp und in einigen Hinsichten nicht perfekt. Allerdings sind wir mit dem jetzigen Stand äußerst zufrieden und freuen uns, dass wir die Hypothese mit unserer Visualisierung bestätigen konnten. Dass sogar weitere Erkenntnisse und Schlussfolgerungen möglich waren, freut uns besonders. Aber natürlich haben wir für den jetzigen Stand auch noch Verbesserungspotenzial. So sollte beispielsweise die Zeitauswahl beim Barchart erheblich verbessert werden. Aktuell wird der Zeitraum mit einem Links- und einem Rechtsklick begrenzt. Das ist suboptimal, weil das Verhalten nicht selbsterklärend ist und zudem bei 365 Balken nur schwer ausgewählt werden kann. Wird beim Anklicken der Balken nicht exakt getroffen, erfolgt keine Auswahl. Eine gute Lösung wäre unserer Meinung nach ein „Range Selector“, der über das Barchart gelegt wird.
Abgesehen von dem genannten Verbesserungspotenzial sind wir mit dem Prototypen aber sehr zufrieden. Mithilfe der Visualisierung haben wir alle wichtigen Funktionalitäten bereitgestellt, um die Hypothese adäquat zu stützen. Zudem konnten durch die ausgewählten Visualisierungen sogar die oben genannten Erkenntnisse gewonnen werden. Weitere Energie würden wir tatsächlich eher in die Beantwortung weiterführender Fragen stecken. Gibt es beispielsweise nur deshalb bei bestimmten Events so erhebliche Ausschläge, weil die Zielgruppe des Events grundsätzlich mehr Instagram-Beiträge verfasst? Oder wie oft erstellen Personen Instagram-Beiträge zu dem gleichen Event, wodurch womöglich Visualisierungen verfälscht werden? Ein anderer Ansatz, der uns im Rahmen der iExpo genannt wurde, war, dass so genannte „Influencer“ nicht am Wochenende Instagram-Beiträge schreiben, da die Zielgruppe an diesen Tagen kleiner ist als unter der Woche - gibt es diesbezüglich eventuell Korrelationen zu Events am Wochenende? Das sind interessante Fragen, die beim Umgang mit unserem Prototypen aufgekommen sind. Generell haben wir eine hohe Motivation diesen Fragen nachzugehen, da dies aber nicht mehr Teil des Visualisierungsprojekts ist und eher in Richtung Data-Science geht, entfällt dieser Teil in der Dokumentation.
Screencast des Prototyps
Der nachfolgende Screencast zeigt den generellen Umgang mit unserer WebApp. Im Rahmen dieser Aufzeichnung werden einige interessante Erkenntnisse, die im entsprechenden Kapitel dieser Dokumentation bereits genannt wurden, gezeigt.
→ Screencast der WebApp mit den in der Dokumentation genannten Erkenntnissen
Resümee
Das Projekt hat uns insgesamt sehr viel Freude bereitet. Insbesondere, da im Rahmen unseres Projekts das Thema Data-Science mitgespielt hat, war unsere private Motivation für diese Semesterarbeit sehr groß. Auch wenn wir im Vergleich zu anderen Vorlesungen wesentlich mehr Zeit für GDV investieren mussten, sind wir rückblickend sehr zufrieden. Unser Prototyp hat annähernd alle Funktionalitäten, die wir implementieren wollten (siehe Kapitel Implementierung) und die Hypothese lässt sich damit effektiv stützen. Neben der reinen Bestätigung der These war es durch unsere ausgewählten Visualisierungen sogar möglich, weitere Erkenntnisse aus der Datenbasis zu ziehen. Genau das war das Ziel, das wir uns zu Beginn des Projekts gesetzt haben, weswegen wir mit unserer Arbeit sehr zufrieden sind.
Interessant wäre natürlich noch, ob das Projekt „Instalife in Mannheim“ auch in anderen Städten so gut funktioniert. Um dieser Frage nachzugehen, würden wir eine Großstadt auswählen, zu der wir keinen Bezug haben und somit keine Kenntnisse vor Ort haben. Das Vorgehen, wie es in diesem Dokument beschrieben ist, bleibt für diesen Versuch gleich. Nach der Betrachtung der Visualisierung würden wir Behauptungen aufstellen und diese anschließend mit dem Internet und Daten über die entsprechende Stadt abgleichen. So könnte man einen Prozentsatz ausrechnen, der die Treffsicherheit unserer WebApp beschreibt. Ein weiterer interessanter Ansatz wäre, wie viele Einwohner eine Stadt generell braucht, damit unser Projekt funktioniert.
Wie bereits im Fazit des Kapitels Implementierung erwähnt, haben wir durch die Visualisierung weiterführende Fragen erkannt, denen wir gerne weiter nachgehen möchten. Aus diesem Grund können wir uns durchaus vorstellen, auch nach Ende dieses Semesters den Prototypen weiterzuentwickeln und so die weitergehenden Fragen mit Visualisierungen beantworten zu können. Eine Veröffentlichung des Prototyps halten wir zum aktuellen Stand aufgrund der mangelhaften Zeitauswahl noch nicht für sinnvoll. Sollten wir den Prototypen aber tatsächlich weiterentwickeln, um so neben der optimierten Zeitauswahl auch noch weitergehende Fragen durch Visualisierungen zu beantworten, können wir uns durchaus vorstellen, das Projekt auf einer Webseite zu veröffentlichen.