Patrick Hentschel, Daniel Eggert, Dario Capuana, Ferhat Ayaydin und Ahmed Warsame
Auswirkung von Bildung auf Kriminalität
Abstract
Thema unseres GDV-Projektes im Wintersemester 2018/2019 waren die 17 Ziele für nachhaltige Entwicklung, welche von den Vereinten Nationen (UN) ins Leben gerufen wurden, um nachhaltige Entwicklung auf ökonomischer, sozialer und ökologischer Ebene zu gewährleisten. Einige der sogenannten SDGs (= UN Sustainable Development Goals) sind Armut zu bekämpfen und für bessere Bildung sowie Gesundheit zu sorgen.
Unser Konzept
In unserem Projekt haben wir uns mit der Frage beschäftigt, ob durch höhere Investitionen in Bildung Gewalt und Kriminalität entgegengewirkt werden kann. Wir haben Daten zu den Bildungsinvestitionen verschiedener Länder in den zurückliegenden Jahren zusammengetragen. Darüber hinaus recherchierten wir die Anzahl der Personen, die in jedem Land die Bildungsabschlüsse primary, secondary und tertiary erreicht haben. Unser Ziel lag darin, anhand der Bildungsinvestitionen der jeweiligen Länder und des World Crime Index (Studie über Kriminalitätsraten und -ereignisse) herauszufinden, ob Länder, die vergleichsweise viel in Bildung investieren, eine geringere Kriminalitätsrate aufweisen können.
Datenquellen und Auswertung
Datenquellen
- entsprechend den SDGs, welche von der UN definiert wurden, haben wir uns bei den Daten zur Bildung für die UNData entschieden, da die UN bereits umfangreiche und zuverlässige Bildungsdaten gesammelt hat.
- da offiziele Kriminalitätsstatistiken seitens der Nationen zu ungenau und nicht verlässlich waren, haben wir den sogenannten Crime Index, der sich unter anderem aus schweren Verbrechen wie Mord und Raubüberfällen zusammensetzt, als Maßstab für Vergleiche zwischen den entsprechenden Ländern genommen.
- als anerkannte Datenquelle haben wir uns beim Bruttoinlandsprodukt (im Folgenden BIP oder GDP) für die Weltbank entschieden.
Auswertung
Datenquelle UNData
Die eingelesenen Daten werden in Pentaho (ETL Tool) verarbeitet. Zuerst mussten die Daten gefiltert und aufgeteilt werden, da nur die Primary,Secondary und Tertiary Abschlüsse für uns relevant waren. Dafür gab es 3 Filteroperationen, die jeweils auf die Spalte “Series” angewandt wurden.
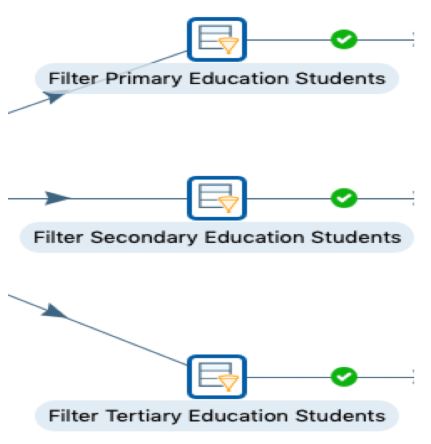 Abbildung:Filteroperationen
Abbildung:Filteroperationen
Jede Filteroperation hat die Spalte jeweils nach folgenden Texten durchsucht:
- Students enrolled in primary education (thousands)
- Students enrolled in secondary education (thousands)
- Students enrolled in tertiary education (thousands)
Wie im Bild zu sehen ist, erzeugt jede Filteroperation einen Stream aus den Daten. Diese bestehen aus den Datensätzen, die in der jeweiligen RegEx (s.o.) bei der Validierung “True” ergeben haben.
Danach werden die Daten aus den Filteroperationen zur Bereinigung an einen nächsten Schritt weitergeleitet. Hier werden die Stringfelder bereinigt. Unter anderem werden in allen Feldern die Kommata innerhalb der Quotes der Strings gelöscht. Des Weiteren werden in der Spalte “Series” die jeweiligen Texte aus dem vorherigen Schritt in die folgenden umbenannt:
- Students enrolled in primary education (thousands) -> Students enrolled in primary education
- Students enrolled in secondary education (thousands) -> Students enrolled in secondary education
- Students enrolled in tertiary education (thousands) -> Students enrolled in tertiary education
Nachdem die Stringreplacements vorgenommen wurden, wird zum Schluss für eine bessere Datenbankkompatibilität das Feld “Region/Country/Area” in “CountryAreaCode” umbenannt.
Aufgrund der Entfernung der Skalierung aus Schritt 2 wurde im Feld “Value” die enthaltene Zahl mit 1000 multipliziert.
Zuletzt werden die einzelnen Datenstreams (primary, secondary und tertiary education) in eine CSV-Datei geschrieben. Am Ende der ETL-Pipeline entstehen aus einer CSV-Datei insgesamt drei CSV-Dateien:
- primary_ed_students.csv
- secondary_ed_students.csv
- tertiary_ed_students.csv
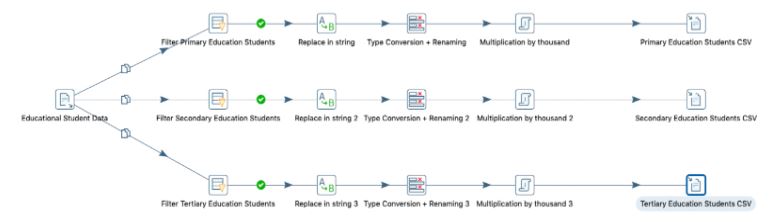 Abbildung:ETL-Pipeline Overview
Abbildung:ETL-Pipeline Overview
Datenquelle Worldbank
Die Problematik hierbei war, dass die Tabelle nicht normalisiert war. Es gab für jedes Jahr eine eigene Spalte. Deshalb entwickelten wir ein Kotlin-Programm, welches eine Transformation durchführte, um eine Spalte “Year” zu erzeugen und die jeweiligen Länder mit den Values und ihrer korrekten Jahreszahl hinzuzufügen.
Zuerst gibt es die Klasse Row, welche eine Zeile aus unserer Datenquelle widerspiegelt:
data class Row(var Country: String, var Series: String,
var IndicatorCode: String, var Source: String,
var year_1960: Double, var year_1961: Double,
... var year_2017: Double)Diese Klasse verfügt über eine Methode, welche sich selbst in die transformierte Version umwandelt. Diese Transformationsfunktion löscht im IndicatorCode zusätzliche Kommata, da diese in MongoDB und bei der Datenverarbeitung zu zusätzlichen Problemen führten. Des Weiteren wurden die Werte der Investitionen, bei denen der Wert “0.0” war, der wiederum nur bedeutet, dass keine Daten hierzu verfügbar waren, durch leere Strings ersetzt, um einen falschen Eindruck bei der Datenvisualisierung zu verhindern.
fun createTransformation(Year: Int, Value: Double): Row_Transformed {
val country: String = this.Country
val series: String = this.Series
val indicatorCode: String = this.IndicatorCode.replace(",", "")
val source: String = this.Source
val year: String = Year.toString()
val value: String = if (Value != 0.0) Value.toString() else ""
return Row_Transformed(Country = country, Series = series,
IndicatorCode = indicatorCode, Source = source,
Year = year, Value = value)
}Zuletzt existiert die Klasse Row_Transformed, welche eine Zeile der bereinigten CSV-Datei widerspiegelt. Im Folgenden ihr Konstruktor und die Funktion, welche wiederum die CSV-Datei generiert:
data class Row_Transformed(var Country: String,
var Series: String,
var IndicatorCode: String,
var Source: String,
var Year: String,
var Value: String) {}
companion object {
fun write_toCSV(x: ArrayList<Row_Transformed>, FILE_PATH:
String = "./../produktiv_daten/cleaned/investment_percentage_GDP.csv",
CSV_HEADER: String = "ID,Country,Series,IndicatorCode,Source,Year"): Unit {
var fileWriter: FileWriter? = null
try {
fileWriter = FileWriter(FILE_PATH)
fileWriter.append(CSV_HEADER)
fileWriter.append('\n')
for (row in x) {
fileWriter.append(row.toString())
}
println("Write CSV successfully!")
} catch (e: Exception) {
println("Writing CSV error!")
e.printStackTrace()
} finally {
try {
fileWriter!!.flush()
fileWriter.close()
} catch (e: IOException) {
println("Flushing/closing error!")
e.printStackTrace()
}
}
}
}Datenquelle Numbeo
Hier mussten die Daten zuerst gescraped werden. Hierfür nutzten wir die Chrome Extension “WebScraper”. Sie ermöglicht auf schnelle zuverlässige Art und Weise statische Seiten zu scrapen. Hierfür werden sogenannte SiteMaps erstellt. Diese benötigen den Link, auf welchem die Daten zu finden sind und lassen sich per XPath oder über die Chrome Developer Tools per “Select” definieren. Wir nutzen hier vor allem die Funktion “Table Scraping”, bei der man nur die Struktur der Tabelle angibt, von welcher die Daten gespeichert werden sollen.
 Abbildung:table Scraping
Abbildung:table Scraping
Dadurch war es innerhalb kürzester Zeit möglich, den entsprechenden Scraper zu erstellen und die Daten in ein CSV-Format zu exportieren.
Die exportierten Sitemaps werden alle im ETL-Tool Pentaho verarbeitet.
 Abbildung:ETL-Tool Pentaho
Abbildung:ETL-Tool Pentaho
Da unser Webscraper automatisch die folgende Spalte in die CSV-Datei hinzufügt: “web_scraper_start_url”, welche über die Information in der URL enthält, aus welchem Jahr die Daten stammen, wird diese Spalte von uns in “year” umbenannt. Danach im Schritt “Replace URL” werden folgende Werte substituiert:
 Abbildung:Substitution
Abbildung:Substitution
Hier ist zu beachten, dass der URL-Builder von numbeo zwar “title=” als Parameter benutzt. Jedoch steht hier das Jahr, welches man auslesen möchte. Kurzfristig gab es zwischen 2014-2015 den Zusatz -Q1 für Quartal, dieser wurde danach jedoch wieder verworfen. Deshalb ist die zusätzliche Substituierung von “-Q1” vorhanden. Anschließend wird die bereinigte CSV-Datei erstellt.
Implementierung
Als Programmiersprache für die Visualisierungen verwenden wir Python, denn Python ist für Datenanwendungen sehr verbreitet und genießt ein hohes Maß an Unterstützung. Die Anwendung selbst wird mit Hilfe eines Python Flask Servers gesteuert. Für die Visualisierung verwenden wir die Python Bibliothek Dash. Diese bietet eine Vielzahl von Visualisierungsmöglichkeiten. Außerdem ist die gute Dokumentation der Bibliothek ein großer Vorteil. In unserem Fall haben wir uns für das Linechart entschieden. Dieses musste optisch an die Pläne angepasst und mit Daten befüllt werden. Die Visualisierungen werden an den Dash Server per HTML-Variable übergeben, welche dieser anschließend rendert. Eine HTML kann auch mehrere Visualisierungen enthalten. Für die Karte verwenden wir die Python Bibliothek Plotly. Da Dash auf Plotly aufbaut, war es uns möglich, die Dash Visualisierungen mit der Plotly Karte in eine HTML-Variable zu packen.
Probleme bei der Implementierung
-
Leaflet und Dash ließen sich nicht auf einem Dashboard verknüpfen. Um alle Visualisierungen auf einem Screen anzeigen zu können, wurde die Leaflet Choroplethenkarte verworfen und eine von Plotly verwendet.
-
Ersatz-Choroplethenkarte besitzt kein Klick-Event, dadurch mussten wir per Workaround die Line Charts an das auf der Karte ausgewählte Land anpassen. Dadurch können die ausgewählten Länder nicht auf der Karte angezeigt werden.
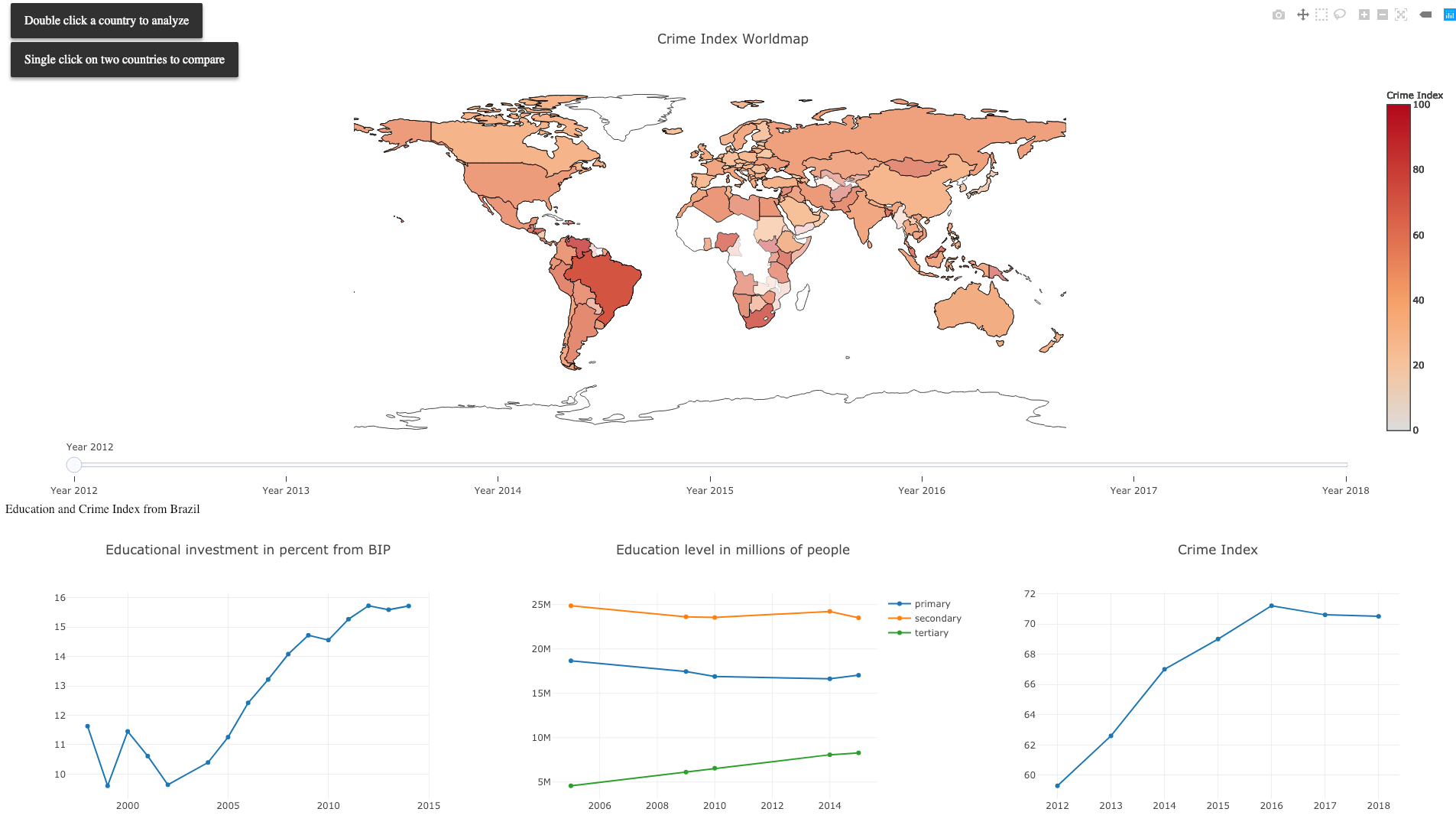
Das Ergebnis
Unsere Webanwendung (GitHub mit Readme) zeigt die Entwicklung der Bildungsinvestitionen und des Crime Index einzelner Länder. Sie ist in zwei Hälften geteilt (siehe Abbildung: Webanwendung) Die obere Hälfte enthält eine Choroplethenkarte, die den Crime Index der einzelnen Länder visualisiert. In der unteren Hälfte sind drei Diagramme zu einem Land, das vorher in der Choroplethenkarte ausgewählt wurde, sichtbar. Alle Diagramme haben eine Zeitachse (in Jahren). Links ist ein Liniendiagramm zu sehen, das die Investitionen in Prozent (Anteil vom BIP) anzeigt. Mittig ist ein Slope Chart angeordnet, der die Anzahl (Angabe in Millionen) der Menschen mit dem entsprechenden Bildungsgrad (primary, secondary und tertiary) anzeigt. Rechts ist ein weiteres Liniendiagramm zum Crime Index angeordnet, um zusätzlich zur Choroplethenkarte die Entwicklung des Crime Index nachvollziehen zu können. Mittig zwischen den beiden Hälften ist ein Slider, mit dem das entsprechende Jahr für die Choroplethenkarte ausgewählt werden kann.
Abbildung:Webanwendung
Erkenntnisse
Im Allgemeinen lässt sich zusammenfassen, dass es keinen erkennbaren Zusammenhang zwischen der Kriminalitätsrate und den Bildungsausgaben gibt. Es ist sogar zu beobachten, dass in manchen Ländern trotz Anstieg der Bildungsinvestitionen der Crime Index auch rapide ansteigt.
Auffälligkeiten gibt es in folgenden Ländern:
Äthiopien:
- Trotz insgesamt ansteigenden Bildungsausgaben steigt der Crime Index an.
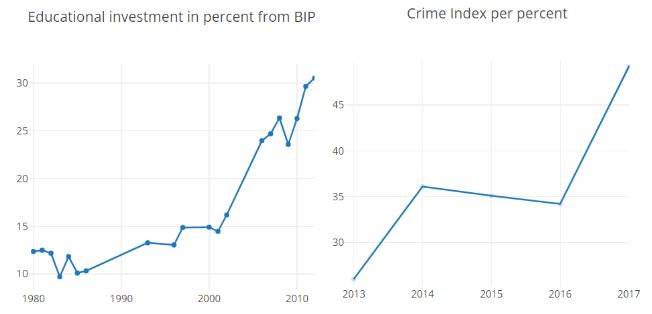 Abbildung: Äthiopien: Bildungsausgaben und Crime index
Abbildung: Äthiopien: Bildungsausgaben und Crime index
Brasilien:
- Hier stiegen die Bildungsausgaben kontinuierlich an, jedoch stieg zugleich der Crime Index an.
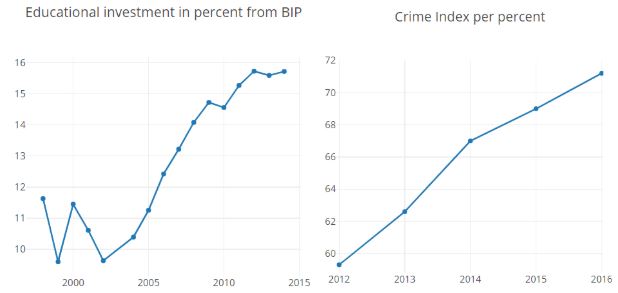 Abbildung: Brasilien: Bildungsausgaben und Crime index
Abbildung: Brasilien: Bildungsausgaben und Crime index
Afghanistan
- Trotz unterschiedlichen Bildungsausgaben sinkt Crime Index kontinuierlich.
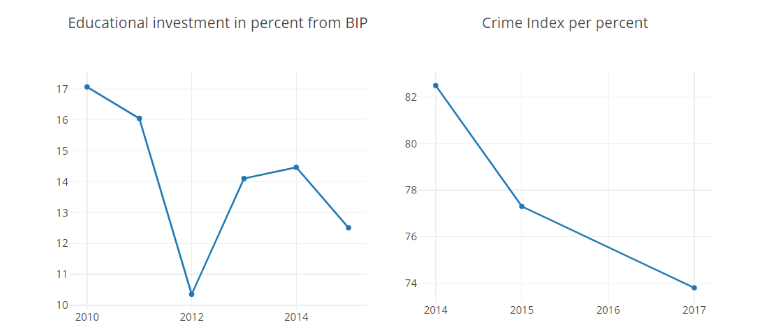 Abbildung: Afghanistan: Bildungsausgaben und Crime index
Abbildung: Afghanistan: Bildungsausgaben und Crime index
Verbesserungsvorschläge
In folgenden Punkten sind Verbesserungsvorschläge bezüglich unserer Webanwendung, die wir während der iExpo bekommen haben:
- eine Snackbar, in welcher der Benutzer beim öffnen der Anwendung eine Einführung bekommt
- Ausgewählte Länder sollten auf der Karte angezeigt und farblich hervorgehoben oder umrandet werden
- Nicht ausgewählte Länder ausgrauen
- Intuitivere Möglichkeit, um ein Land statt zwei auszuwählen
- Stärkere Markierung der ausgewählten Länder in der Überschrift der Line Charts
Fazit
Unsere Vermutung, dass steigende Investition in Bildung weniger Kriminalität zur Folge haben würde, hat sich nicht bewahrheitet. Unsere Annahme: Um Kriminalität effizient entgegenzuwirken, sind Maßnahmen gegen beispielsweise Drogenkriege in Brasilien notwendig. Solche Maßnahmen oder Faktoren wären somit höher priorisiert als der Faktor Bildung, um nachhaltige Ergebnisse zu erzielen. Ebenso vermuten wir, dass Investitionen in Bildung keine erkennbaren Auswirkungen von heute auf morgen haben können, da Bildung und ihre erhofften positiven Ergebnisse einige Jahre beanspruchen können.
Credits
- Studenten: Patrick Hentschel, Daniel Eggert, Dario Capuana, Ferhat Ayaydin und Ahmed Warsame
- Kurs: Grundlagen der Datenvisualiserung Wintersemester 2018/2019
- Dozent: Prof. Dr. Till Nagel, Hochschule Mannheim