Lisa Balsen, Fabian Hoppe, Romeo Türemis, Julian Wernz, Manuel Wirth
Neckarstadt KliMA
Im Zuge des voranschreitenden Klimawandels rückt im Bereich der Stadtplanung und Neugestaltung immer mehr der Begriff der Klimaresilienz in den Vordergrund. Ein besonders relevanter Faktor dabei ist die Flächenversiegelung, welche vor allem in Großstädten und Ballungszentren ein Problem ist. Der Versiegelungsgrad wirkt sich erheblich auf die Aufheizung bzw. anschließende Abkühlung von urbanen Gebieten aus. Dieses Projekt analysiert diesen Zusammenhang am Beispiel der Mannheimer Neckarstadt und stellt den Versuch an, eine umfangreiche, interaktive Visualisierung zu bieten, welche den Sachverhalt so präsentiert, dass Erkenntnisse aus den dargestellten Daten gezogen werden können. Die Ergebnisse des Projekts deuten darauf hin, dass ein Zusammenhang zwischen der Flächenversiegelung und der Temperatur besteht, allerdings ließen sich nicht alle Hypothesen bestätigen, was darauf hindeutet, dass weitere Einflussfaktoren hinzukommen.
Dieses Projekt ist im Rahmen des Kurses “Grundlagen der Datenvisualisierung” im Sommersemester 2024 an der Hochschule Mannheim unter der Leitung von Prof. Dr. Till Nagel entstanden.
Einführung
Die einzige deutsche Stadt, mit einem höheren Versiegelungsgrad als Mannheim, ist Ludwigshafen.
Die Stadt Mannheim ist mit ihrem Versiegelungsgrad von 66,39 % ein Negativbeispiel dafür, wie Stadtplanung die klimatischen Umstände in bewohnten Gebieten beeinflussen kann. Gerade aus diesem Sachverhalt heraus haben wir die Motivation gefunden, dieses Projekt zu konzipieren und umzusetzen. Zu Beginn des Projekts entwickelten wir ein Grobkonzept. Die Messwerte des sMArt City Mannheim Sensornetzes sollten dazu verwendet werden, eine interaktive Visualisierung der Temperaturwerte für den Mannheimer Stadtkreis zu entwickeln, um dann in Kombination mit Versiegelungsdaten eine Korrelation sichtbar zu machen. Dieses Konzept basierte auf zwei Arbeitshypothesen:
- H1: Mannheims hoher Versiegelungsgrad wirkt sich stark negativ auf die Klimaresilienz der Stadt aus, insbesondere die Erhitzung/Abkühlung.
- H2: Bestimmte Mannheimer Stadtteile sind besonders stark von hohen Temperaturen betroffen.
Im Verlauf der Konzeptionsphase ergänzten wir diese um eine weitere Hypothese:
- H3: An besonders heißen Tagen ist nach anschließender Abkühlung die Temperaturdifferenz bei unterschiedlich stark versiegelten Flächen am höchsten.
Während der explorativen Datenanalyse (EDA) stellten wir fest, dass das sMArt City Mannheim Sensornetz eine besonders hohe Dichte von Sensoren im Bereich der Neckarstadt aufweist. Deshalb haben wir unser Konzept insofern angepasst, dass wir für die Beantwortung der Fragestellungen nur die Neckarstadt betrachten. Schon in diesem frühen Stadium der Konzeption hatten wir die Idee, zusätzlich zu einer interaktiven Visualisierung, auch einen geführten Modus bereitzustellen, der den Betrachter durch vordefinierte Data Stories dazu anregen soll, mit den Daten zu interagieren und eigene Hypothesen aufzustellen und zu prüfen.
Im Laufe der EDA und inkrementellen Entwicklung des Prototyps unserer Visualisierung wurde das Konzept mehrfach angepasst, überarbeitet, gekürzt und eine finale Version erstellt. Mehr zum Prozess und dem fertigen Prototyp folgt in den kommenden Kapiteln.
Daten
Wir nutzen für unser Projekt die Messdaten des Mannheimer Stadtklimanetzes. Auf diese Daten konnten wir über das Open Data Portal des sMArt City Projekts zugreifen. Täglich wird hier seit dem 20.02.2024 ein neuer Datensatz veröffentlicht, welcher die Messdaten der Sensornetz-Stationen des jeweiligen Tages in Form von CSV-Dateien enthält. In diesen Dateien sind die Messwerte der betreffenden Station im 10-Minuten-Takt über den ganzen Tag aufgeführt. Gemessen werden hierbei unter anderem die Parameter Luftfeuchte, Windrichtung und Windgeschwindigkeit. Wir beschränkten uns hierbei auf die Temperaturdaten.
Da jede Messstation eine eigene Datei für jeden Tag erhält, handelt es sich um eine sehr große Menge an Dateien. Aktuell stehen bei circa 150 verfügbaren Tagen mit jeweils ungefähr 200 Messstationen fast 30000 CSV-Dateien zur Verfügung. Für einen besseren Überblick und zur explorativen Datenanalyse innerhalb Tableau nutzten wir daher ein Python-Script, um alle Messdaten in einer großen CSV-Datei zu bündeln. Die relevanten Metadaten zu den Stationen erhielten wir ebenfalls über das Open Data Portal. Diese liegen in Form einer Excel-Tabelle vor und enthalten die für uns notwendigen Standortinformationen der Stationen.
Zusätzlich zu den Smart City Daten hatten wir weiterhin Zugriff auf eine API der MVV, welche deutlich mehr Messstationen abdeckt. Es handelt sich jedoch teils um noch nicht am finalen Standort installierte Sensoren, so dass einige der Meßwerte noch nicht vollständig waren und einige Messstationen keinen georäumilchen Standort aufwiesen. Daher haben wir uns entschieden, die bereits überprüfte Teilmenge an Stationen vom Open Data Portal zu verwenden, um aussagekräftige Untersuchungen durchzuführen. Zudem hatten wir bereits einen Workflow zum Zusammenführen der Daten entwickelt, sodass der zusätzliche Aufwand, die API anzusprechen, für uns nicht lohnenswert war.
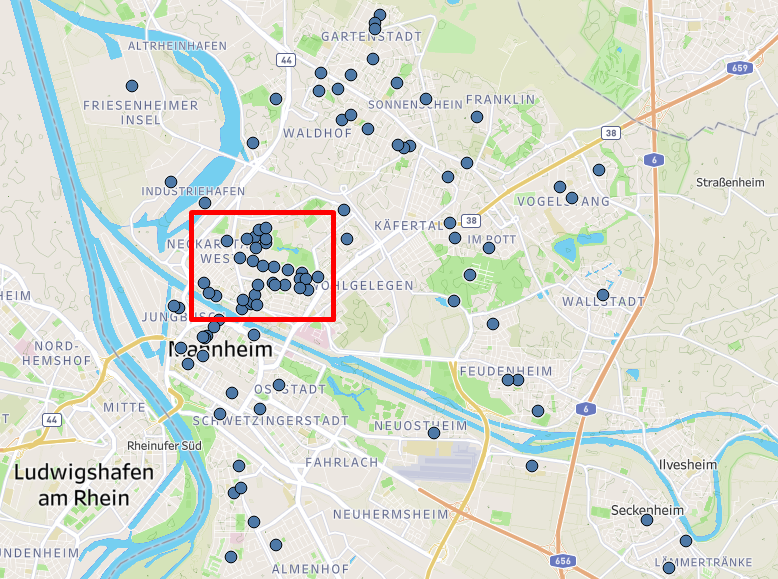
Im Zuge der explorativen Datenanalyse mit Tableau konnte festgestellt werden, dass in vielen Stadtteilen nur wenige Messstationen vorhanden sind. Eine Ausnahme bildet die Neckarstadt mit einer hohen Dichte von 29 Messstationen auf relativ kleinem Raum. Zusätzlich gibt es in diesem Gebiet große Unterschiede im Grad der Versiegelung, der Bebauung und der Flächenbegrünung. Während im Bereich der Alten Feuerwache der überwiegende Teil der Fläche bebaut ist, stellt der Herzogenriedpark mit seinen naturnahen Grün- und Erholungsflächen das Gegenstück dar. Aufgrund der hohen Sensordichte in Kombination mit den unterschiedlichen örtlichen Gegebenheiten haben wir uns entschieden, dieses Gebiet in unserem Projekt zu betrachten und beschränkten uns ab diesem Zeitpunkt auf die Daten dieser 29 Messstationen.
Datenaufbereitung
Zu Beginn der Analyse der Temperaturdaten fiel schnell auf, dass es Ungereimtheiten gibt.
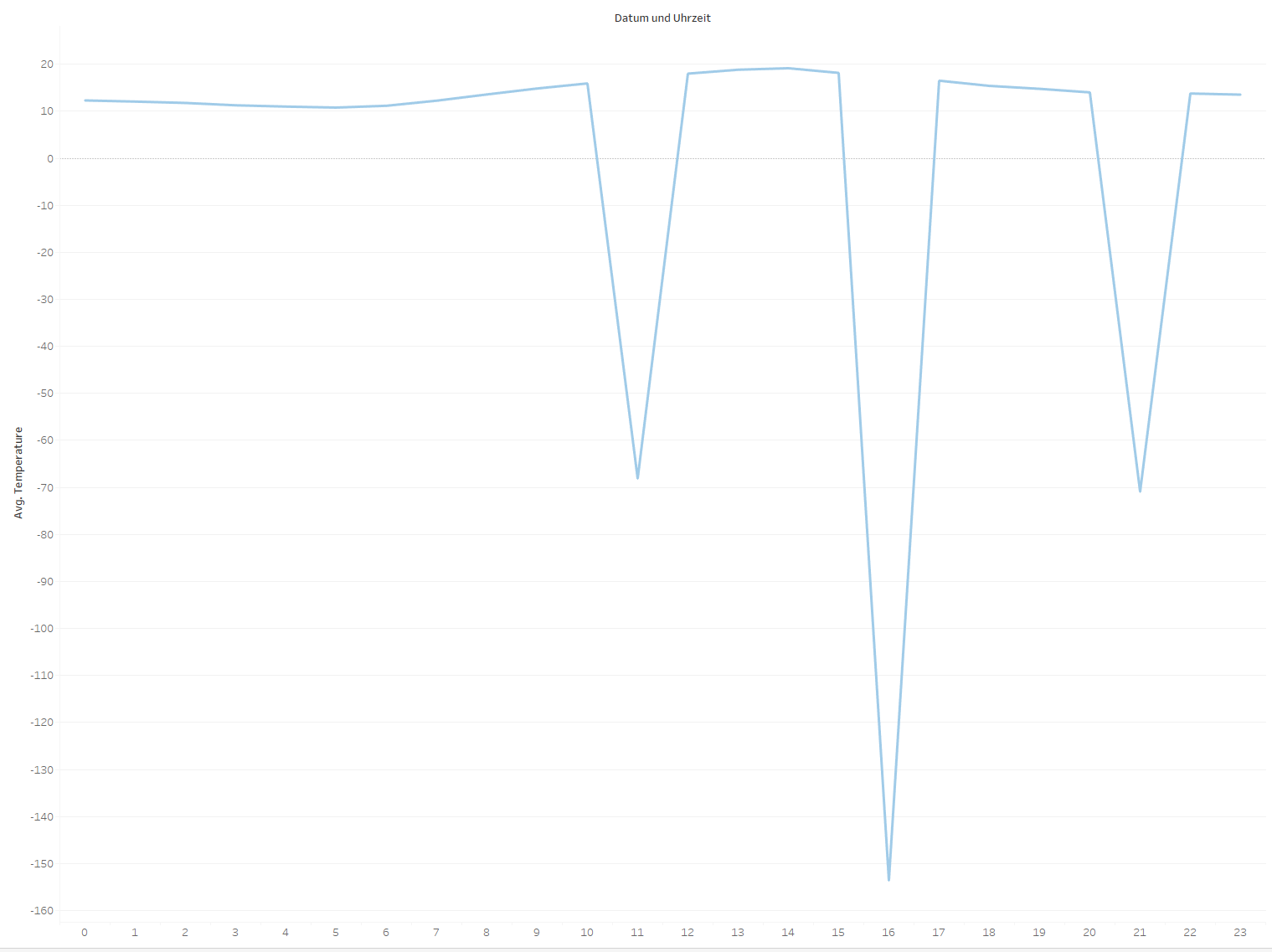
Auf der gezeigten Abbildung ist der Verlauf der stündlichen Durchschnittstemperatur einer Messstation über einen Tag zu sehen. Es ist zu erkennen, dass die ermittelte Durchschnittstemperatur an mehreren Zeitpunkten hunderte Grad Celsius im Minus liegt. Dies liegt daran, dass die Stationen fehlerhafte Messungen mit dem Wert “-999.0” angeben.
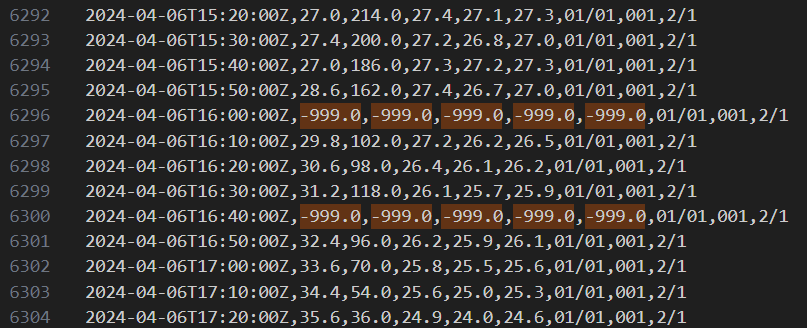
Diese Fehlerhaften Messwerte filterten wir zunächst in Tableau zur Datenanalyse und schließlich auch in unserem Prototypen heraus und beschränkten uns auf die restlichen validen Messwerte, um eine stündliche Durchschnittstemperatur zu ermitteln. Außerdem stellten wir fest, dass die angegebene Uhrzeit von der Zeit in unserer Zeitzone abwich und passten sie für alle Einträge entsprechend an.
Fokus auf den Zeitpunkt mit der größten Abkühlung
Der größte Unterschied der (von Tableau ermittelten) stündlichen Durchschnittstemperatur zwischen den Messstationen konnte am Morgen des 07.04.2024 festgestellt werden. Hier betrug die Differenz zwischen der wärmsten und der kältesten Messstation um 6 Uhr morgens knapp 5 Grad auf einer Strecke von weniger als einem Kilometer.
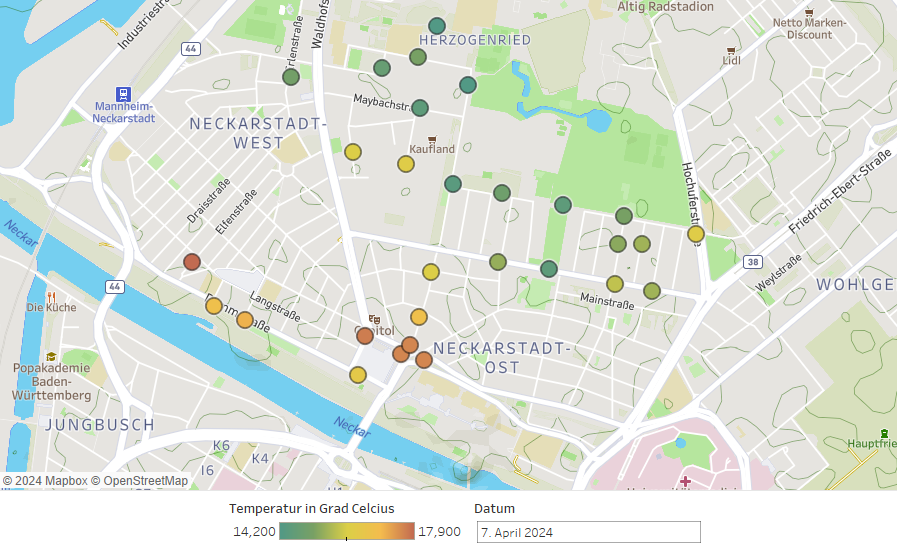
Da der größte Wertunterschied um 6 Uhr morgens gemessen wurde, d.h. ungefähr zur Zeit des Sonnenaufgangs, als die Temperatur am stärksten abgekühlt war, beschränken wir uns im Folgenden auf diesen Zeitpunkt. Interessant für uns war auch die Tatsache, dass die größte Differenz in der Nacht nach dem wärmsten 6. April seit Beginn der Wetteraufzeichnungen in Mannheim auftrat. Da wir keine Vergleichsdaten von vorherigen Sommertagen hatten, führte uns diese Erkenntnis zu unserer Hypothese H3.
Prozess
In einem gemeinsamen Team-Treffen haben wir festgelegt, dass wir die Temperaturentwicklung und dabei vor allem die Abkühlung nach heißen Tagen in der Neckarstadt durch Visualisierungen zeigen wollen. Außerdem sollte der Fokus auf dem Vergleich der Abkühlung in verschiedenen Teilen der Neckarstadt liegen. Daraus sollte dann die Beziehung zwischen Abkühlung und Grünflächen an den Standorten der Stationen gezogen werden. Auf Basis dieser Entscheidung hat jedes Teammitglied Mockups erstellt, wie wir die Abkühlung am besten mit Visualisierungen zeigen können.
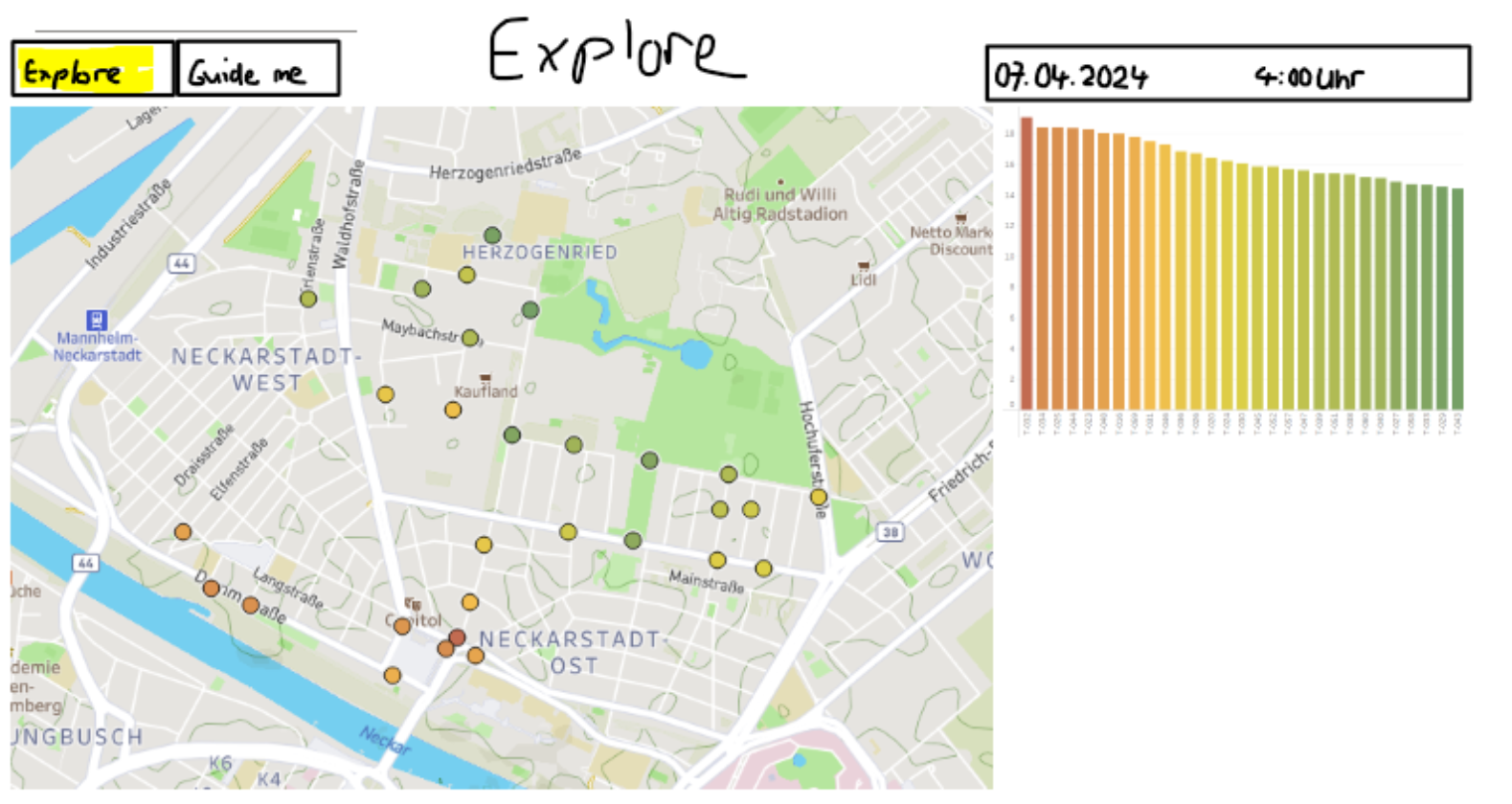
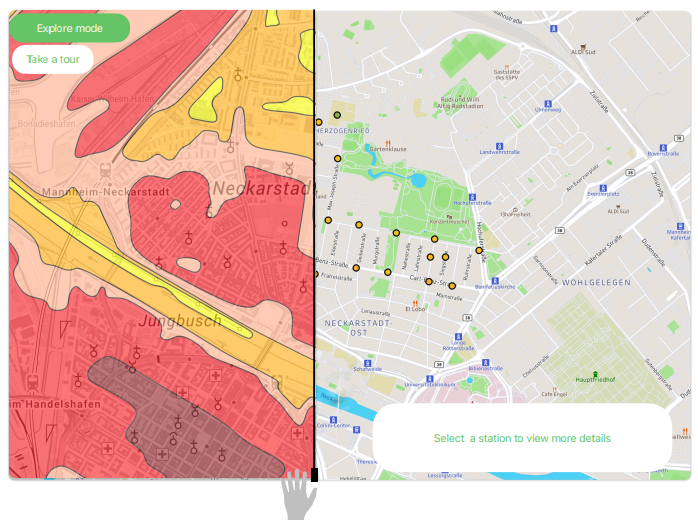
Durch dieses Vorgehen gab es einige Ideen für Visualisierungen, die teilweise sehr ähnlich waren, aber sich auch unterschieden haben. Große Einigkeit herrschte beim Verwenden einer Karte, in der die verschiedenen Stationen mit ihrer Temperatur gezeigt werden. Nach einem Gespräch mit Herr Nagel haben wir interessante Aspekte aus den Mockups festgehalten. Es ist aber auch aufgefallen, dass viele Ideen in der kurzen Projektzeit nicht umzusetzen sind. Deshalb haben wir uns darauf fokussiert ein Minimum Viable Product (MVP) zu entwerfen und dafür einige Komponenten festgehalten, mit denen wir die Abkühlung in der Neckarstadt zeigen wollen. Auf jeden Fall soll es eine Karte geben, die die Standorte und die Abkühlung der Stationen visualisiert. Außerdem sollen die Stationen anhand einer Visualisierung miteinander verglichen werden können. Anstatt weitere Daten für Versiegelung und Grünflächen zu verwenden und diese zu visualisieren, haben wir uns für das MVP dafür entschieden, die eingezeichneten Grünflächen auf der Karte sowie die örtliche Erkundung mithilfe von Google Street View zu verwenden, um Schlüsse zwischen Abkühlung und Grünflächen zu ziehen.
Aufgrund dieser festgelegten Komponenten hat die Entwicklung unseres Prototyps begonnen. Dabei konnte im ersten Schritt eine erste Version einer Karte und eines Balkendiagramms umgesetzt werden.
Im nächsten Schritt haben wir ein Liniendiagramm hinzugefügt, das den Temperaturverlauf für die Stationen über den ganzen Tag zeigt. Außerdem wurden erste Interaktionen mit den Visualisierungen eingeführt.
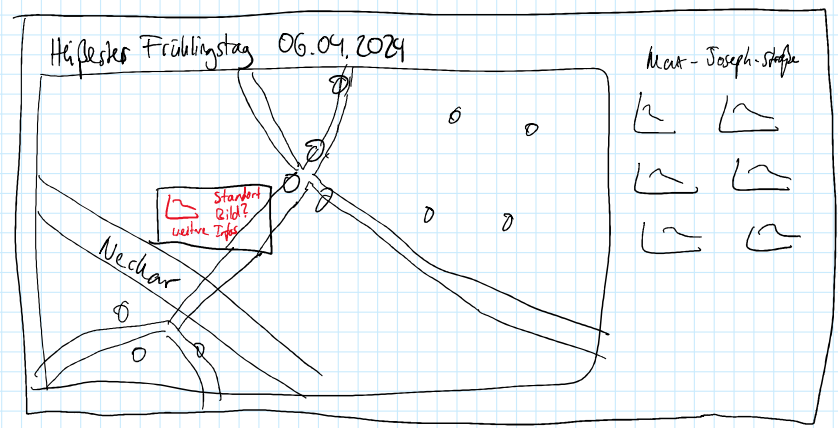
In einer weiteren Konsultation mit Herrn Nagel wurde die Idee von verschiedenen Data-Stories entwickelt. In einem Guide-Modus sollen dem Nutzen interessante Daten-Sets gezeigt werden. Anhand einer ersten Data-Story, die sich auf die Max-Joseph-Straße am 07.04. fokussiert, wurde dieser Guide-Modus in den Prototypen eingebaut, indem die relevanten Stationen hervorgehoben wurden und ein Erklärtext dem Nutzer die Besonderheit dieser Data Story erklärt. Dieser Guide-Modus soll neben einem Explore-Modus stehen, indem die Nutzer die Daten eigenständig erkunden können. Richtung Ende des Projektes wurden zwei weitere Data-Stories mit zugehörigen Erklärungstexten zusammengestellt.
Mit dem Prozess ist ein Prototyp entstanden, der die Abkühlung in der Neckarstadt zeigt und dem Nutzer dabei einen Überblick über interessante Daten gibt. Dazu ist es für den Nutzer aber auch möglich, die Daten selbst zu erkunden.
Prototyp
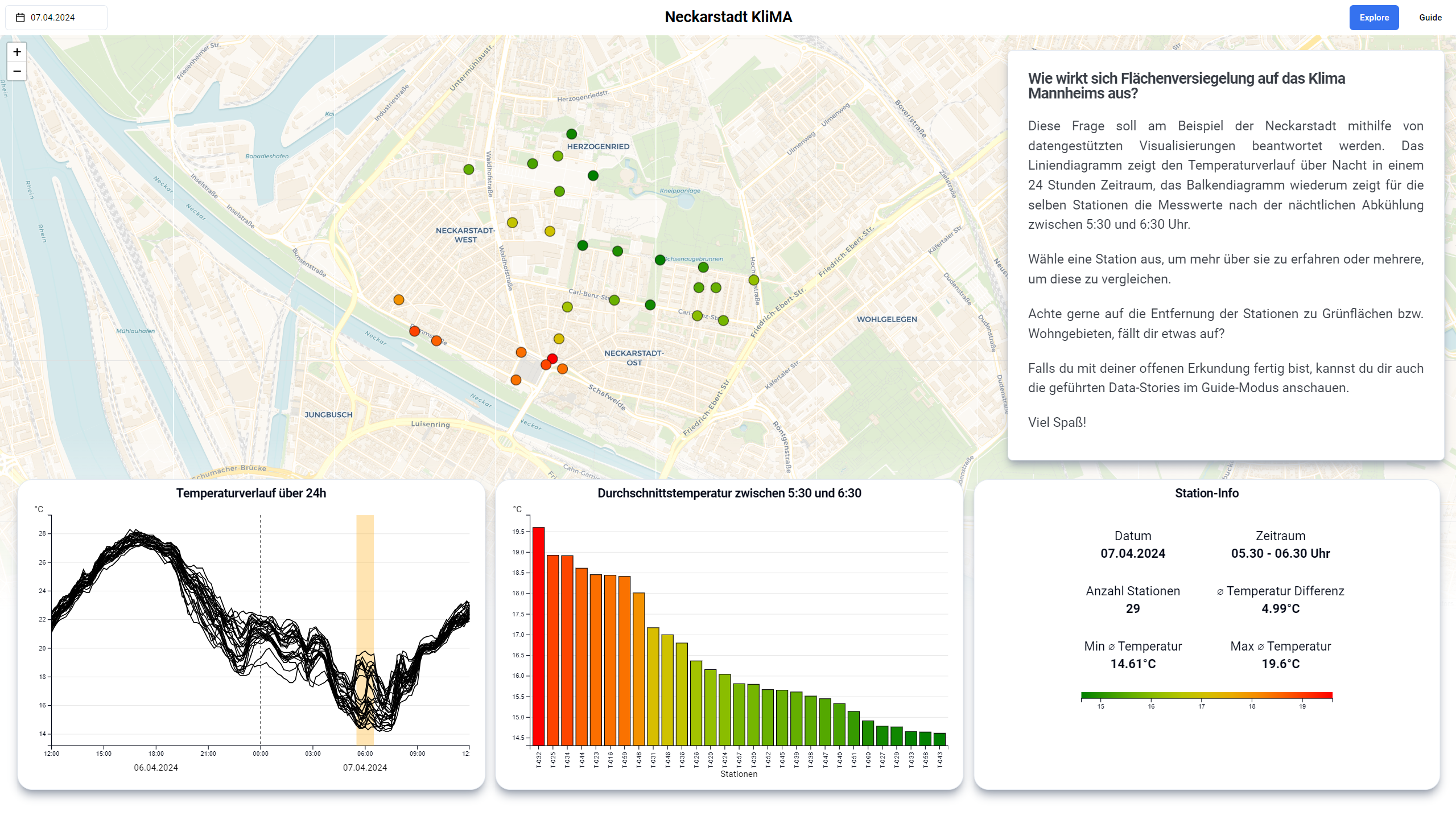
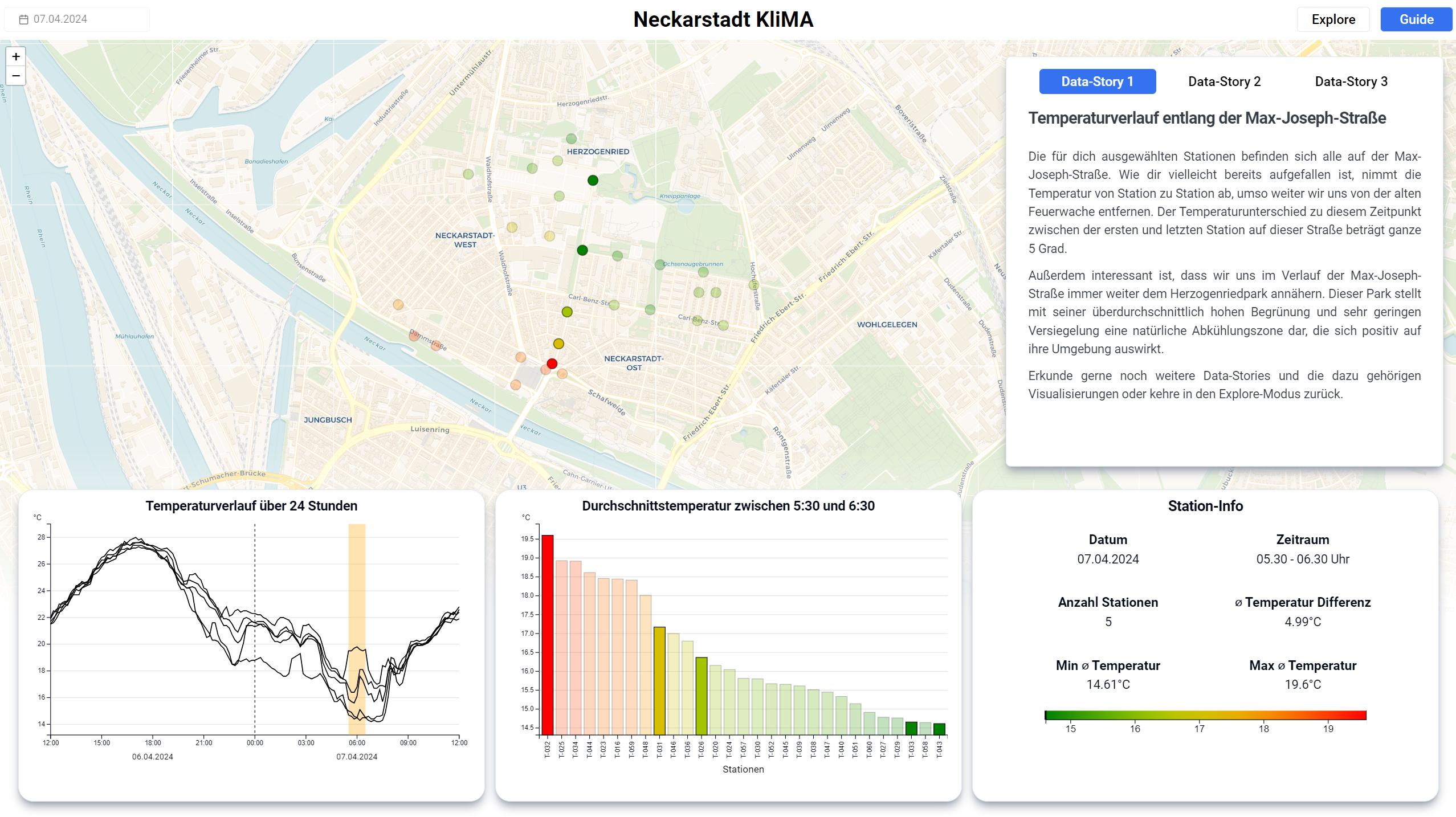
Das Dashboard verfügt über zwei Modi. Den Explore- sowie den Guide-Modus. Beide Modi haben unterschiedliche Anwendungszwecke, sie gleichen sich aber in ihrem generellen Aufbau und werden in Kürze erklärt. Standardmäßig ist der Explore-Modus ausgewählt.
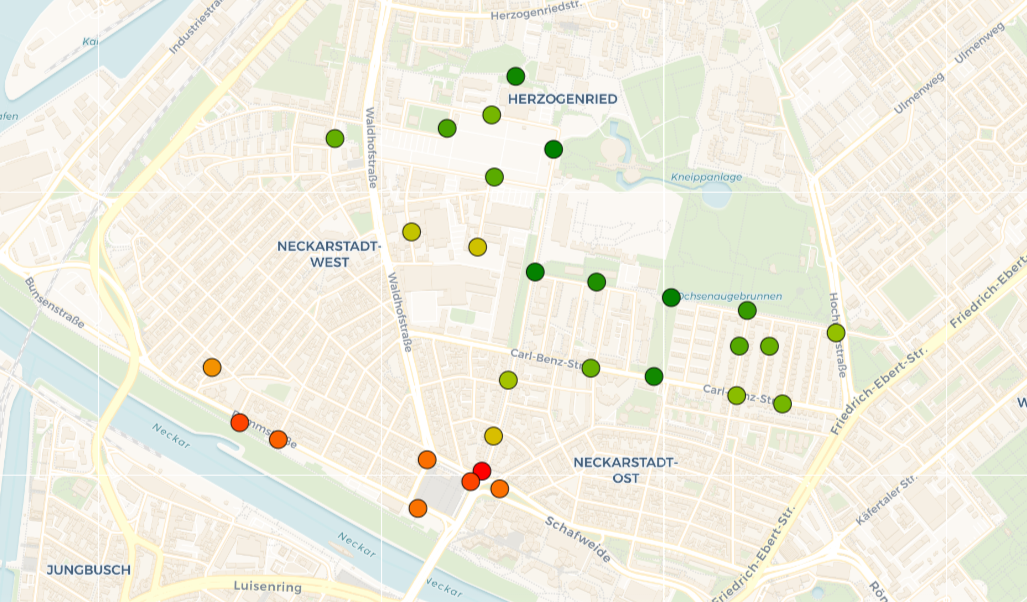
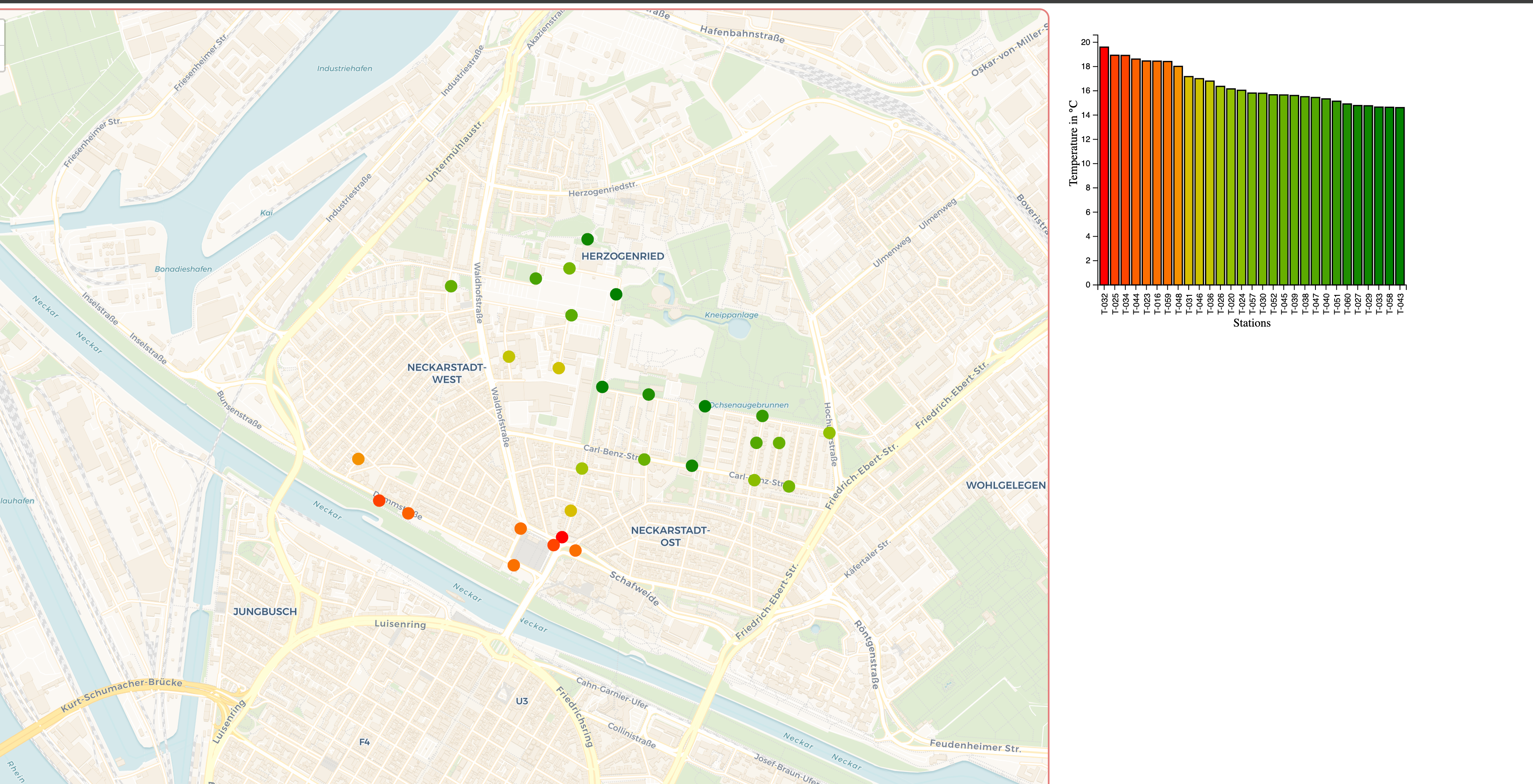
Der Prototyp besteht aus mehreren Komponenten. Zentraler Bestandteil des Dashboards ist eine interaktive Karte, auf der die Messstationen der Neckarstadt markiert sind. Die Farbe der Punkte repräsentiert die Durchschnittstemperatur um 6 Uhr morgens. Zur Ermittlung dieses Wertes nutzten wir die Temperaturdaten von 5:30 Uhr bis 6:30 Uhr und bildeten daraus den Durchschnitt. Die Farbskala reicht von grün (kühl) über gelb bis rot (warm) und wird für jeden Tag dynamisch skaliert, so dass auch bei geringen Temperaturunterschieden ein Muster erkennbar werden kann. Der Bereich der Karte lässt sich verschieben, es lässt sich heran- und wegzoomen und der Nutzer kann mit den einzelnen Stationen interagieren. Bewegt der Nutzer seine Maus über einen dieser Punkte erhält er einen Tooltip mit relevanten Informationen zur jeweiligen Station wie beispielsweise der Durchschnittstemperatur. Durch Anklicken einer Messstation kann diese ausgewählt werden, wobei alle anderen Messstationen ausgegraut werden. Daraufhin lässt sich durch einen erneuten Mausklick in Kombination mit der Strg-Taste eine weitere Station zur Auswahl hinzufügen. Mit einem Klick auf den Rest der Karte kann die Auswahl zurückgesetzt werden. Auf diese Art und Weise wird die interaktive Karte zum zentralen Bedienelement des Dashboards. Neben der reinen Steuerung der ausgewählten Messstationen können mit der Karte ebenfalls geografische Muster im Bezug auf die Temperatur erforscht werden. Es lässt sich außerdem der gewünschte Tag mithilfe eines Datepickers einstellen.
Auf der unteren Seite des Dashboards befinden sich drei Elemente, die sich direkt auf die getroffene Wahl der Stationen und den Tag beziehen und sich dementsprechend anpassen.
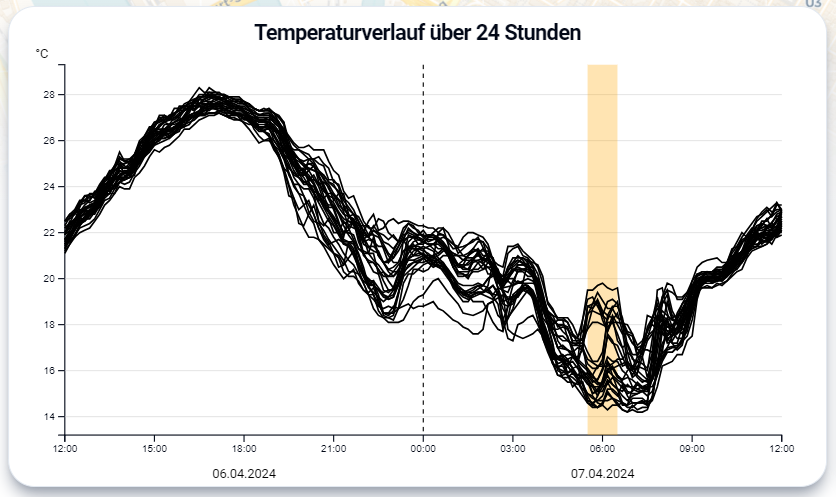
Auf der linken Seite ist ein Liniendiagramm, das den Temperaturverlauf der ausgewählten Messstationen zeigt. Wir entschieden uns für ein Liniendiagramm, da hierbei Verläufe sehr gut erkennbar und vergleichbar werden und weil es eine gängige Methode zur Temperatur-Visualisierung über Zeit darstellt, die intuitiv verständlich ist. Als Alternative hatten wir Small Multiples in Betracht gezogen, bei denen jedoch die teilweise sehr feinen Unterschiede im Temperaturverlauf nur schwer ablesbar waren. In Gelb markiert ist der Zeitraum, der in unserer Arbeit betrachtet wird und aus dem die Durchschnittstemperatur gebildet wird. Um diesen Wert nachvollziehen zu können, ist es jedoch essentiell, auch die Temperaturentwicklung am Mittag des Vortages zu berücksichtigen. Zu diesem Zeitpunkt stieg die Temperatur an, um anschließend bis zu unserem ausgewählten Zeitraum kontinuierlich abzukühlen. Daher wurde ein Zeitraum von 12 Uhr des Vortages bis 12 Uhr des betreffenden Tages gewählt. Aufgrund dessen, dass ein solcher Zeitraum nicht üblich ist, haben wir diesen Tageswechsel mit einer gestrichelten Linie und dem jeweiligen Tagesdatum unter der X-Achse gekennzeichnet. Um die Feinheiten im Verlauf der Temperatur noch besser sichtbar zu machen, entschieden wir uns, die Skalierung der Y-Achse dynamisch für jeden Tag anzupassen. Eine statische Skala hätte von Temperaturen um den Gefrierpunkt bis zu Temperaturen von circa 34 Grad reichen müssen und hätte kaum Rückschlüsse auf Temperaturunterschiede zugelassen. Die Linien von nicht ausgewählten Messstationen werden in Grau angezeigt. Somit können Temperaturverläufe einerseits isoliert betrachtet werden, auf der anderen Seite aber auch in der Gesamtheit der Linien eingeordnet und verglichen werden. Dies kann in der Vorstellung des Prototyps nachvollzogen werden.
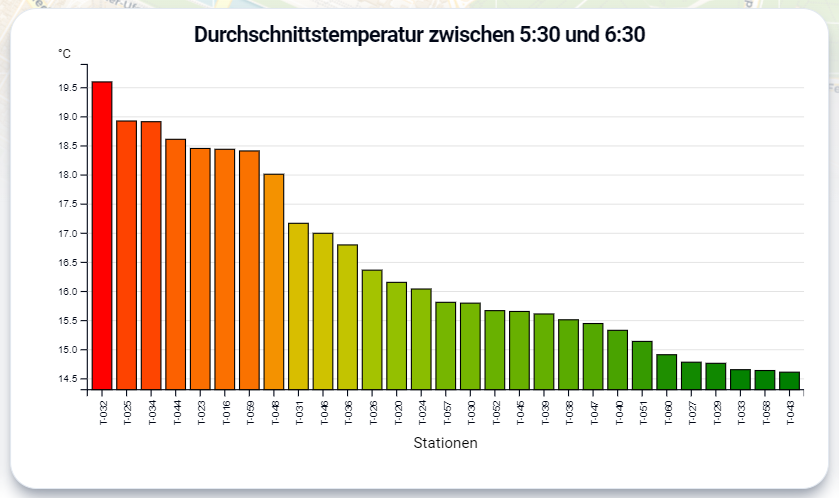
In der Mitte befindet sich ein sortiertes Säulendiagramm, das die Durchschnittstemperatur aller Stationen während des betrachteten Zeitraums miteinander vergleicht. Die Temperaturskala ist ebenfalls dynamisch gewählt, damit Temperaturunterschiede von wenigen Grad erkennbar werden. Interessant ist hierbei, dass die Temperatur einmal auf der Höhe der Säule abgebildet ist, gleichzeitig aber auch die Farbe der Säule bestimmt. Die Farben stimmen mit denen auf der Karte überein und schaffen so eine weitere Verbindung der beiden Elemente. Zusätzlich zur geografischen Einordnung einer Station lässt sie sich auf diese Weise auch besser Gesamtheitlich in der Neckarstadt einordnen, da nicht ausgewählte Stationen hier ebenfalls grau markiert sind. Daher entschieden wir uns für diese Visualisierung. Eine aufwändigere Visualisierung unter Verwendung von Boxplots konnte zeitlich nicht mehr angegangen werden.

Das letzte Element, welches direkt von der Karte beeinflusst wird, befindet sich auf der rechten Seite und gibt Informationen über Stationen. Bei nur einer ausgewählten Station lässt sich hier die Durchschnittstemperatur, der Name der Station sowie das Datum und der Zeitraum ablesen. Zusätzlich gibt es einen Google Street View Button. Hiermit kann sich der Nutzer den Standort genau anschauen und somit versuchen, die örtlichen Gegebenheiten miteinander zu vergleichen. Bei mehreren ausgewählten Stationen ändern sich die angezeigten Informationen. Statt der Durchschnittstemperatur einer Station wird nun die minimale und maximale Durchschnittstemperatur sowie deren Differenz für die Auswahl angezeigt. Außerdem befindet sich auf diesem Element die Legende der Farbskala.
Weiterhin gibt es eine Textkomponente, die dem Nutzer die behandelte Fragestellung erklärt, Kontext gibt und erklärt, welche Optionen dieser hat.
Allgemein lässt der Explore-Modus zu, dass der Nutzer frei erkundet und seine eigenen Erkenntnisse und Hypothesen überprüft. Orientiert wurde sich hierbei an dem Prinzip “Overview first, zoom and filter, then details-on-demand” von Ben Shneiderman. Am Anfang gibt es einen Überblick mit allen Stationen, dann lassen sie sich filtern und anschließend erhält der Nutzer Details über das Informationselement. Der Guide-Modus hingegen soll den Nutzer an die Hand nehmen und ihn durch ausgewählte Data Stories führen. Dabei werden alle Elemente automatisch an die passende Data Story angepasst und eine Auswahl anderer Stationen oder eines anderen Tages ist nicht mehr möglich. Die Textkomponente arbeitet die Stories auf. Die Data-Stories werden innerhalb des Vorstellungsvideos gezeigt, können jedoch aus Platzgründen in dieser Dokumentation nicht ausführlich erläutert werden. Viele der Punkte finden sich aber inhaltlich in unseren Erkenntnissen wieder.
Implementierung
Für die Implementierung unseres Prototypen haben wir uns für die Implementierung als Web-Anwendung mit React.js entschieden. Durch die Verwendung von React haben wir eine gute Kontrolle über die Erstellung unseres Dashboards aus mehreren Visualisierungen. Außerdem lassen sich die Visualisierungen und weitere Dashboard-Elemente durch die Erstellung dieser als Komponenten in React sehr gut kapseln und in das Dashboard einbinden. Alternativen zur Verwendung von React wären das Implementieren des Dashboards mit Vanilla JavaScript oder die Verwendung von Angular gewesen. Für React haben wir uns letztendlich entschieden, da im Team bereits Vorerfahrung mit React aus Projekt- und Praxissemester bestand und es deutliche Vorteile gegenüber der Verwendung von Vanilla JavaScript bietet.
Für die Erzeugung von Visualisierungen haben wir uns für die JavaScript-Bibliothek D3.js entschieden. Diese ermöglicht große Flexibilität im Erstellen von Visualisierungen und Interaktionen mit den Visualisierungen. Außerdem wollten wir uns schon früh auf eine Visualisierungsbibliothek festlegen, um mehr Einarbeitungszeit zu haben und dafür hat sich D3.js wegen der Flexibilität am besten für uns geeignet. Alternativen wären noch JavaScript Bibliotheken wie Chart.js oder Python-Bibliotheken wie Plotly gewesen. Wegen mehr Vorerfahrung in JavaScript und React sowie aus dem Grund der frühen Festlegung der Bibliothek fiel unsere Entscheidung letztendlich auf D3.js.
Die Kartenvisualisierung ist ein zentraler Bestandteil unseres Prototypen. Für diese haben wir uns für die JavaScript-Bibliothek Leaflet.js entschieden. Diese bietet eine gute Integration in React.js und bietet außerdem verschiedene Karten und Visualisierungsmöglichkeiten. Außerdem ist Leaflet.js sehr fokussiert auf Leichtigkeit und gute Performance bei der Darstellung von Karten. Als Alternative dazu haben wir uns noch Mapbox GL als Alternative angeschaut. Mit dieser Bibliothek ist es möglich 3D-Karten zu erzeugen. Letztendlich haben wir aber wegen mangelnder Übersichtlichkeit und schlechterer Performance dagegen entschieden.
Die Daten sind als CSV-Datei in das Projekt eingebunden. Wir haben die Entscheidung gegen eine Datenbank getroffen, weil wir von der EDA bereits einen funktionierenden Workflow hatten, um die Daten als CSV bereitzustellen. Außerdem lief der Prototyp nach dem initialen Laden performant und deshalb haben wir keinen Grund gesehen, auf eine Datenbank umzusteigen.
Als Entwicklungsumgebung hat jedes Teammitglied je nach Vorkenntnissen die JetBrains IDEs IntelliJ oder WebStorm verwendet. Diese IDEs bzw. Code Editoren bieten umfangreiche Unterstützung bei der Entwicklung mit JavaScript bzw. React. Zur Versionierung unseres Programmcodes haben wir Git bzw. GitHub zum Teilen des Codes verwendet.
Erkenntnisse
Mithilfe unseres finalen Prototypen konnten wir unsere Hypothesen prüfen und sind dabei auf interessante Ergebnisse gestoßen. Am Beispiel der Max-Joseph-Straße, unserer ersten Data-Story, konnten wir zeigen, dass ein deutlicher Temperaturunterschied zwischen Stationen bestand, die unterschiedlich stark versiegelte Standorte haben. Die Messwerte zeigten, dass umso näher eine Station an der Alten Feuerwache steht, desto höher sind auch ihre gemessenen Temperaturwerte zwischen 5:30 - 6:30 Uhr. Dies traf besonders auf den 07.04.24 zu, was zur Entscheidung beitrug, diesen Tag für die Data Story auszuwählen.

Dieses Muster konnte an diversen Tagen reproduziert werden. Die Abbildung zeigt hierbei einen kleinen Ausschnitt.
Aufgrund unserer Fokussierung auf die Neckarstadt konnten wir unsere Hypothese H2, welche eine Betrachtung mehrerer Mannheimer Stadtteile erfordert, nicht prüfen.
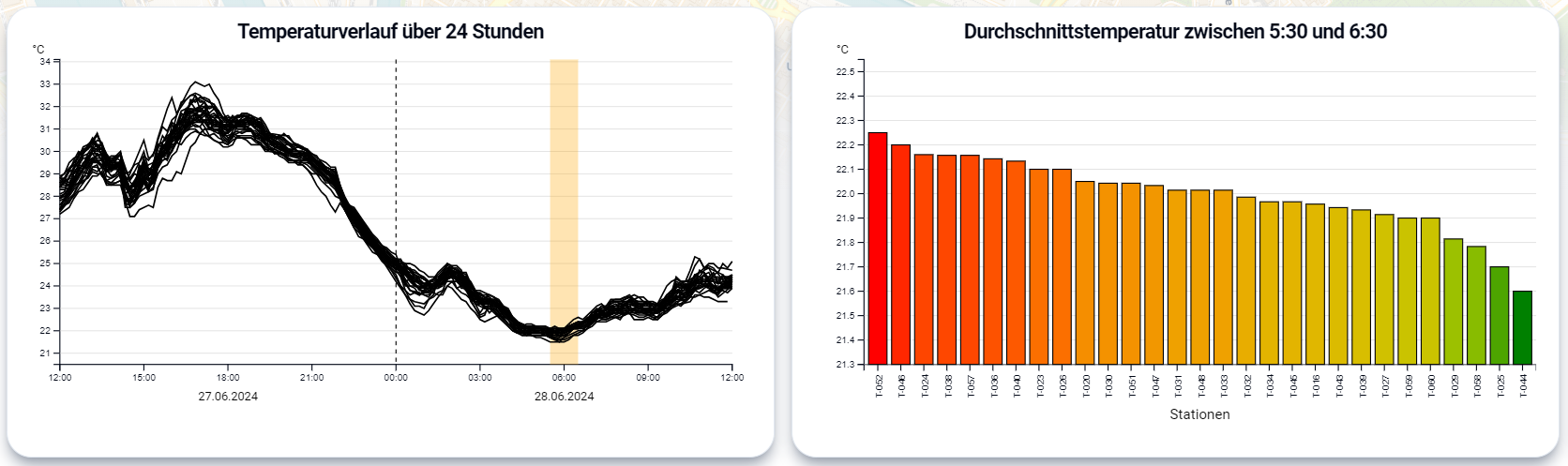
Unsere Hypothese H3 konnten wir nicht bestätigen. Ein beispielsweise besonders heißer Tag im Zeitraum der Messungen war der 27.06.24, die gemessene Höchsttemperatur unserer Sensorauswahl an diesem Tag betrug ca. 33 Grad Celsius. Die Differenz der Messwerte am darauffolgenden Morgen betrug allerdings nur 1 Grad Celsius. Wie im Liniendiagramm erkennbar ist, sind die Messwerte aller Stationen sehr nah beieinander ohne erkennbare Zusammenhänge zur Versiegelung.
Unsere dritte Data-Story, welche in der Vorstellung des Prototyps gezeigt wird, hat bereits einen Hinweis darauf gegeben, dass bei unserer Betrachtung zahlreiche Einflussfaktoren für die Interpretation der Daten herangezogen werden können. Ein weiteres Beispiel für eine Ausnahme unserer Annahmen ist die Neckarwiese. Trotz der sehr geringen Versiegelung der Neckarwiese sind die dort gemessenen Temperaturen ähnlich hoch wie an Orten mit hoher Versiegelung, was darauf schließen lässt, dass allein die geringe Versiegelung nicht ausreicht, um Abkühlung zu begünstigen.
Fazit
Während des Projekts ist es uns gelungen, eine interaktive Visualisierung zu konzipieren, iterativ weiterzuentwickeln und zu implementieren. Der finale Prototyp bietet eine Vielzahl von Funktionen an, um die Daten selbst zu explorieren und eigene Thesen zu prüfen. Mithilfe der Data Stories wird dem Nutzer eine geführte Variante der Visualisierung angeboten.
Allerdings mussten wir auch zahlreiche Anpassungen und auch Kürzungen vornehmen. Leider ist es uns nicht gelungen, eine solide Datenquelle für den Versiegelungsgrad der Neckarstadt ausfindig zu machen oder aus anderen Daten abzuleiten. Es würde eine deutliche Verbesserung des Prototypen bedeuten, wenn eine solche Datenquelle ergänzt werden würde.
Durch die zeitliche Begrenzung des Projekts war es uns auch nicht möglich, weitere Faktoren wie die Windgeschwindigkeit oder Luftfeuchtigkeit zur Betrachtung hinzuzuziehen. Eine Weiterentwicklung unseres Prototypen könnte mithilfe dieser Daten und zusätzlicher Diagramme eine umfangreichere Analyse der Aufheizung und Abkühlung ermöglichen. Daraufhin wäre es auch interessant, die gesamte Stadt Mannheim als Datenbasis zu verwenden, besonders durch die hohe Anzahl an Sensoren, die aktuell noch installiert bzw. normiert werden, birgt das Projekt noch viel Potenzial zur Erweiterung.